5 Best RAG Evaluation Tools for Developer Workflows (2025)

TL;DR: RAG evaluation requires assessing both retrieval (context relevance, precision, recall) and generation (faithfulness, answer quality, hallucination detection). RAG observability demands visibility into retrievals, tool calls, LLM generations, and multi-turn sessions with robust evaluation and monitoring. This guide compares the top five platforms: Maxim AI, LangSmith, Arize Phoenix, Traceloop, and Galileo.
Table of Contents
- Why RAG Evaluation Matters
- Key Capabilities of RAG Evaluation Tools
- The 5 Best RAG Evaluation Tools
- Platform Comparison
- Choosing the Right Tool
- Conclusion
Why RAG Evaluation Matters
Retrieval-Augmented Generation (RAG) systems combine document retrieval with language model generation to provide grounded, contextually relevant responses. According to research published in Evaluating RAG systems: A comprehensive framework, effective assessment requires measuring retrieval and generation quality independently to identify specific pipeline failures.
The right observability tool transforms your isolated AI systems into transparent, debuggable pipelines. Without proper instrumentation, teams cannot diagnose whether poor responses stem from irrelevant retrievals, insufficient context, or generation failures.
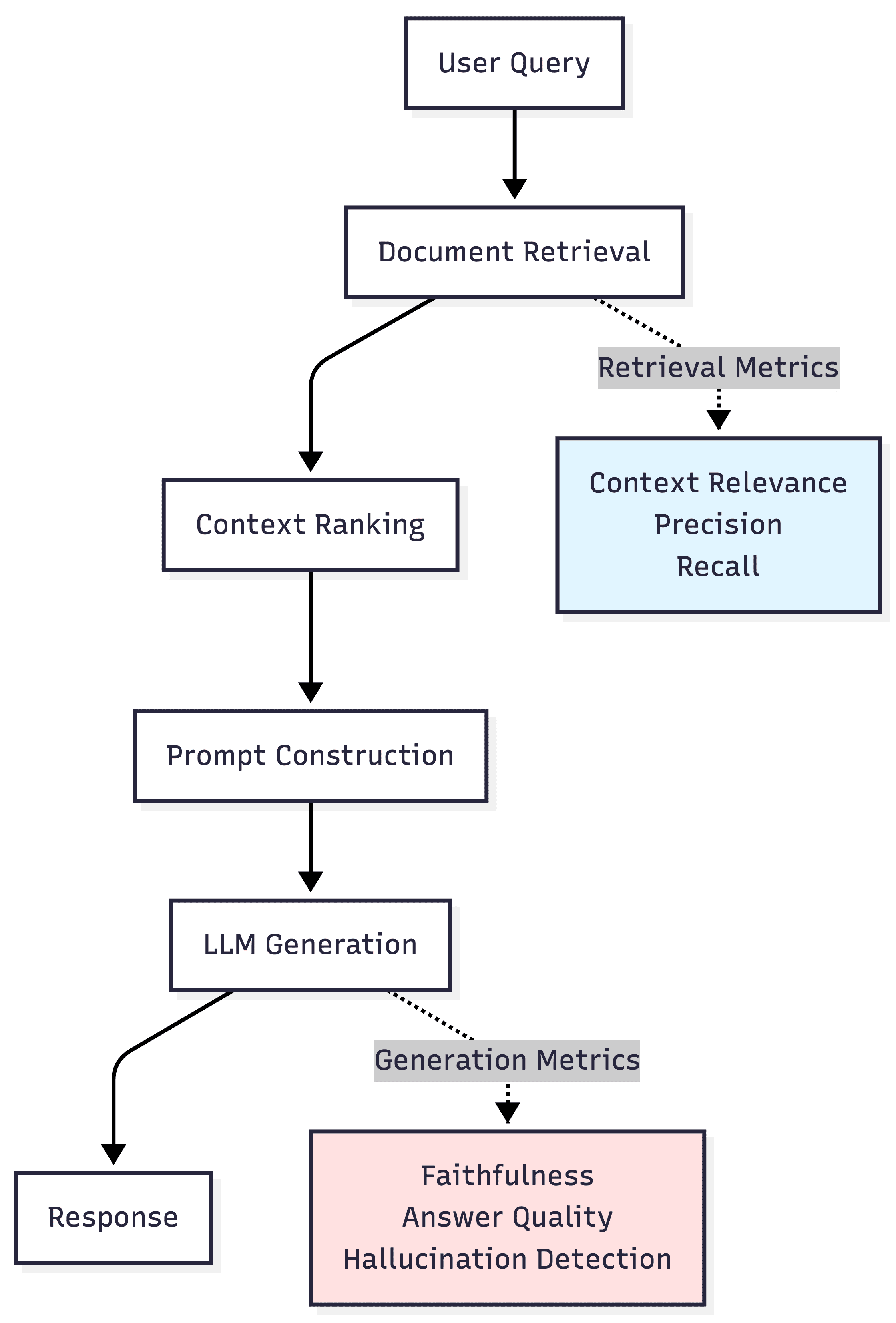
Key Capabilities of RAG Evaluation Tools
Effective RAG evaluation platforms provide comprehensive metric coverage across retrieval metrics (context relevance, precision, recall), generation metrics (faithfulness, answer relevance, hallucination detection), and end-to-end quality assessment.
According to research on conversational AI evaluation, production systems require multi-turn conversation tracking since most applications involve context accumulation across exchanges. Evaluation tools must support flexible evaluation methods, including LLM-as-judge, deterministic rules, human-in-the-loop workflows, and statistical measures.
Production observability remains critical for detecting silent degradation from data drift, performance regressions, and edge cases not covered in test sets
The 5 Best RAG Evaluation Tools
Maxim AI
Platform Overview
Maxim is an end-to-end platform for agent observability, evaluation, and simulation, designed to help teams ship AI agents reliably. Unlike point solutions, Maxim AI provides comprehensive lifecycle management spanning experimentation, simulation, evaluation, and production monitoring.
Key Features
Full-Stack RAG Workflow Support
Maxim supports the complete RAG development lifecycle through integrated products. Playground++ enables rapid prompt iteration with version control and A/B testing. Agent Simulation tests RAG systems across hundreds of scenarios before deployment. The unified evaluation framework combines machine evaluators with human review workflows. Production observability provides real-time monitoring with distributed tracing and automated quality checks.
Multi-Level Evaluation Granularity
Maxim enables evaluation at span-level (individual retrieval steps), trace-level (complete request-response cycles), and session-level (multi-turn conversations). This flexibility allows teams to pinpoint exact failure points in complex multi-agent RAG systems.
Flexi Evaluators for RAG Metrics
Maxim's evaluator store includes pre-built evaluators for context relevance, answer faithfulness, hallucination detection, citation accuracy, and response completeness. Teams can create custom evaluators without code through the UI.
Advanced Data Curation
The Data Engine provides multi-modal dataset management, continuous curation from production logs, human annotation workflows, and automated data labeling integration. Maxim's data curation capabilities enable teams to import datasets, enrich them with human feedback, and create targeted data splits for specific scenarios.
Cross-Functional Collaboration
Maxim emphasizes collaboration between AI engineers, product managers, and QA teams through no-code evaluation configuration, custom dashboards for business metrics, shared workspaces, and role-based access controls.
Best For
Maxim is ideal for teams requiring end-to-end lifecycle management, cross-functional collaboration, multi-agent RAG architectures, and enterprise deployment with SOC 2 compliance.

LangSmith
Platform Overview
LangSmith is an observability and evaluation platform developed by the LangChain team, offering deep integration with the LangChain ecosystem. According to LangSmith's documentation, the platform provides detailed visibility into LangChain-based RAG applications.
Key Features
LangSmith offers detailed trace visualization showing nested execution steps, pre-configured evaluators for relevance and correctness metrics, LLM-as-judge support for natural language evaluation criteria, and dataset management tools for creating evaluation sets from production traces.
Best For
LangSmith works best for teams heavily invested in the LangChain ecosystem who need detailed observability into RAG pipelines. The platform focuses primarily on observability rather than systematic quality improvement.
Arize Phoenix
Platform Overview
Arize Phoenix is an open-source observability platform built on OpenTelemetry standards, providing vendor-agnostic tracing for LLM applications. According to Phoenix's documentation, the platform accepts traces via standard OTLP protocol, enabling integration with existing observability stacks.
Key Features
Phoenix offers OpenTelemetry-native architecture compatible with Datadog, New Relic, and Honeycomb, RAG-specific evaluators for retrieval quality assessment, first-class instrumentation for LangChain, LlamaIndex, DSPy, and Haystack, a prompt playground for testing variations, and specialized hallucination detection evaluators.
Best For
Phoenix is ideal for teams prioritizing OpenTelemetry-based observability and vendor neutrality. The open-source nature (7,800+ GitHub stars) makes it suitable for organizations with existing observability infrastructure.
Traceloop
Platform Overview
Traceloop is an LLM reliability platform built on OpenTelemetry and powered by OpenLLMetry, an open-source SDK for LLM observability. According to Traceloop's documentation, the platform provides end-to-end tracing with support for 20+ LLM providers.
Key Features
Traceloop features OpenLLMetry SDK for automatic instrumentation, automated RAG performance metrics tracking (context precision, recall, faithfulness), multi-language support (Python, TypeScript, Go, Ruby), automated evaluations on pull requests or in production, and granular cost and performance monitoring.
Best For
Traceloop suits engineering teams requiring OpenTelemetry-based observability with flexible deployment options (cloud, on-premises, air-gapped) and multi-language support.
Galileo
Platform Overview
Galileo is an AI evaluation and observability platform emphasizing real-time guardrails powered by proprietary Luna models. According to Galileo's platform documentation, the solution focuses on ensuring reliability and safety for production AI applications.
Key Features
Galileo provides Luna-powered evaluations with sub-200ms latency, specialized RAG metrics (context adherence, chunk attribution, completeness), real-time guardrails blocking harmful outputs, auto-tuned metrics based on live feedback, and visual agent debugging for multi-step workflows.
Best For
Galileo is designed for enterprise teams requiring real-time guardrails, low-latency evaluations, and comprehensive security features for complex RAG systems.
Platform Comparison
| Feature | Maxim AI | LangSmith | Arize Phoenix | Traceloop | Galileo |
|---|---|---|---|---|---|
| Full Lifecycle Support | ✅ Complete | ⚠️ Observability Focus | ⚠️ Observability Focus | ⚠️ Observability Focus | ⚠️ Evaluation Focus |
| Multi-Level Evaluation | ✅ Span/Trace/Session | ✅ Trace | ✅ Trace | ✅ Trace | ✅ Trace |
| Pre-Built RAG Evaluators | ✅ Extensive | ✅ Good | ✅ Good | ⚠️ Limited | ✅ Extensive |
| No-Code Configuration | ✅ Yes | ❌ No | ❌ No | ❌ No | ⚠️ Partial |
| OpenTelemetry Support | ✅ Yes | ⚠️ Limited | ✅ Native | ✅ Native | ❌ No |
| Cross-Functional Collaboration | ✅ Full Support | ⚠️ Engineer-Focused | ⚠️ Engineer-Focused | ⚠️ Engineer-Focused | ⚠️ Engineer-Focused |
| Simulation Capabilities | ✅ AI-Powered | ❌ No | ❌ No | ❌ No | ❌ No |
| Data Curation | ✅ Data Engine | ⚠️ Basic | ⚠️ Basic | ⚠️ Basic | ⚠️ Basic |
| Deployment Options | ✅ Cloud/On-Prem/Air-Gapped | ✅ Cloud/Hybrid | ✅ Cloud/Self-Hosted | ✅ Cloud/On-Prem/Air-Gapped | ✅ Cloud |
Choosing the Right Tool
Selecting the appropriate RAG evaluation platform depends on your development stage, team composition, and technical requirements.
For Early Development: Teams in prototyping stages should prioritize experimentation support. Maxim's Playground++ enables rapid prompt iteration with version control and A/B testing capabilities without production complexity.
For Pre-Production Testing: Before deployment, comprehensive simulation becomes critical. Maxim's Agent Simulation allows testing across hundreds of scenarios and user personas, identifying edge cases before they impact users.
For Production Deployment: Live applications require robust observability. While all platforms provide monitoring, Maxim's observability suite offers real-time quality checks, distributed tracing, and automated alerts integrated with the full development lifecycle.
Framework Considerations: LangSmith excels for LangChain-exclusive teams. Maxim AI, Phoenix, and Traceloop support multiple frameworks without lock-in.
Team Structure: Engineering-only teams can use any platform. Cross-functional teams benefit from Maxim's no-code evaluation configuration and custom dashboards, enabling product managers to define quality criteria without engineering dependencies.
OpenTelemetry Requirements: Teams with existing observability infrastructure should evaluate Phoenix and Traceloop for native OTLP support, though Maxim also provides OpenTelemetry compatibility.
Conclusion
RAG evaluation demands comprehensive visibility into retrieval quality, generation accuracy, and end-to-end system performance. The five platforms reviewed provide different approaches tailored to specific use cases.
Maxim AI provides the only end-to-end solution spanning experimentation, simulation, evaluation, and production observability. The platform's unique capabilities in AI-powered agent simulation, multi-level evaluation granularity, and cross-functional collaboration tools eliminate the tool sprawl that slows RAG development.
For teams requiring LangChain integration, LangSmith offers detailed tracing. Arize Phoenix and Traceloop provide OpenTelemetry-native observability for vendor-neutral architectures. Galileo delivers enterprise-focused evaluation with real-time guardrails.
The optimal choice depends on your framework compatibility, team structure, deployment constraints, and whether you need comprehensive lifecycle management or point solutions. Teams building production-grade RAG applications benefit from Maxim's unified approach, which accelerates development through integrated workflows from experimentation to production monitoring.
Explore Maxim AI's platform to see how end-to-end RAG evaluation can transform your development workflow, or schedule a demo to discuss your specific requirements with our team.
Further Reading
Maxim AI Resources
- Mastering RAG Evaluation Using Maxim AI
- Complete Guide to RAG Evaluation: Metrics, Methods, and Best Practices for 2025
- Evaluator Store: Pre-Built and Custom Metrics
- Data Engine for Dataset Management
Industry Research
- ARES: An Automated Evaluation Framework for Retrieval-Augmented Generation Systems (Carnegie Mellon University)
- RAGAS: Automated Evaluation of Retrieval Augmented Generation
- Benchmarking Large Language Models in Retrieval-Augmented Generation (Microsoft Research)
- A Survey on Evaluation of Large Language Models (Tsinghua University)
Ready to elevate your RAG evaluation workflow? Sign up for Maxim AI to start building more reliable AI applications, or book a demo to explore how our platform can accelerate your team's development velocity.


