Best Braintrust Alternative in 2025: Why Teams Choose Maxim AI

Introduction
As AI agents transition from experimental prototypes to production-critical systems, teams need comprehensive platforms that support the entire AI lifecycle. While evaluation is essential, building reliable agents requires simulation capabilities, detailed tracing, and seamless collaboration between engineering and product teams.
Braintrust has established itself as a platform for evaluation and prompt testing, particularly for RAG and prompt-first applications. However, teams building agent-based workflows often need capabilities that extend beyond single-turn evaluation to include multi-turn simulation, node-level debugging, and human-in-the-loop quality assurance.
This guide examines Maxim AI as a comprehensive alternative, focusing on verified differentiators in agent simulation, observability, and enterprise readiness based on the official Maxim vs Braintrust comparison.
Table of Contents
- Introduction
- High-Level Overview: Maxim vs Braintrust
- Maxim's End-to-End Stack for AI Development
- Observability and Tracing Capabilities
- Evaluation and Testing: Where Maxim Excels
- Prompt Management for Production Agents
- Enterprise Readiness and Compliance
- Pricing: Seat-Based vs Usage-Based Models
- Real-World Impact: Thoughtful's Journey
- When to Choose Which Platform
- Conclusion
High-Level Overview: Maxim vs Braintrust
Maxim and Braintrust both provide structure and evaluation capabilities for LLM-based systems, but they differ significantly in architecture, intended use cases, and deployment preferences.
| Category | Maxim | Braintrust |
|---|---|---|
| Primary Focus | Agent Simulation, Evaluation & Observability, AI Gateway | Evaluation and Prompt Testing for RAG & prompt-first apps |
| Best For | Teams building production-ready agents, with humans in the loop | Devs needing fast iteration on prompts, with LLM-as-a-judge |
| Compliance | SOC2, HIPAA, GDPR, ISO27001 | SOC2 |
| Pricing Model | Usage + Seat-based | Usage-based ($249/mo for 5GB) |
Understanding the Core Distinction
The fundamental difference lies in scope and target workflows. Braintrust focuses on evaluation and prompt testing, making it well-suited for developers building RAG applications who need rapid iteration on prompts with LLM-as-a-judge evaluation.
Maxim takes an end-to-end approach designed for teams deploying agent-based workflows in production. The platform encompasses simulation, detailed tracing, and human-in-the-loop evaluation, addressing the complete lifecycle from experimentation through production monitoring.
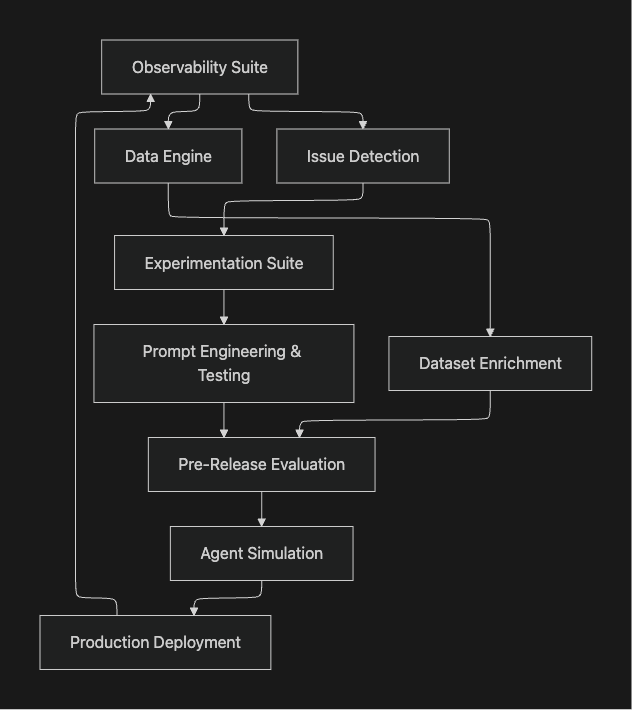
Maxim's End-to-End Stack for AI Development
At Maxim, the platform comprises four integrated components covering the complete AI lifecycle:
1. Experimentation Suite
The experimentation suite enables teams to rapidly, systematically, and collaboratively iterate on prompts, models, parameters, and other components of their compound AI systems during the prototype stage. This helps teams identify optimal combinations for their specific use cases.
Key capabilities include:
- Prompt CMS: Centralized management system for organizing and versioning prompts
- Prompt IDE: Interactive development environment for prompt engineering
- Visual Workflow Builder: Design agent-style chains and branching logic visually
- External Connectors: Integration with data sources and functions for context enrichment
2. Pre-Release Evaluation Toolkit
The pre-release evaluation framework offers a unified approach for machine and human evaluation, enabling teams to quantitatively determine improvements or regressions for their applications on large test suites.
Core features:
- Evaluator Store: Access to Maxim's proprietary pre-built evaluation models
- Custom Evaluators: Support for deterministic, statistical, and LLM-as-a-judge evaluators
- CI/CD Integration: Seamless integration with development team workflows for automated testing
- Human-in-the-Loop: Comprehensive frameworks for subject matter expert review
3. Observability Suite
The observability suite empowers developers to monitor real-time production logs and run them through automated evaluations to ensure in-production quality and safety.
Monitoring capabilities:
- Real-Time Logging: Capture and analyze production interactions as they occur
- Automated Evaluations: Run quality checks on production data continuously
- Node-Level Tracing: Debug complex agent workflows with granular visibility
- Alert Integration: Native Slack and PagerDuty integration for immediate issue notification
4. Data Engine
The data engine enables teams to seamlessly tailor multimodal datasets for their RAG, fine-tuning, and evaluation needs, supporting continuous improvement of AI systems.
Observability and Tracing Capabilities
Observability becomes critical when deploying agents in production. The ability to trace, debug, and monitor agent behavior determines how quickly teams can identify and resolve issues.
Feature Comparison
| Feature | Maxim | Braintrust |
|---|---|---|
| OpenTelemetry Support | ✅ | ✅ |
| Proxy-Based Logging | ✅ | ❌ |
| First-party LLM Gateway | ✅ (open-source) | ✅ |
| Node-level Evaluation | ✅ | ❌ |
| Agentic Evaluation | ✅ | ✅ |
| Real-Time Alerts | ✅ (Native Integration) | ✅ (via webhooks) |
The Node-Level Advantage
Maxim's key distinction: Fine-grained, per-node decision tracing and alerting, critical for debugging complex agent workflows. This capability allows teams to pinpoint exactly where in a multi-step agent process issues occur, rather than only seeing high-level traces.
Braintrust provides high-level tracing but currently lacks node visibility and native integration for alerts on Slack and PagerDuty. For teams managing complex agent architectures, this granularity proves essential for maintaining reliability.
Proxy-Based Logging
Maxim supports proxy-based logging through integrations like LiteLLM, enabling teams to capture logs without modifying application code. This approach simplifies instrumentation and supports legacy systems that may be difficult to update.
Open-Source LLM Gateway
Maxim's Bifrost gateway is open-source, providing teams with transparency into how their AI traffic is managed and the flexibility to customize gateway behavior for specific requirements. Learn more in the Bifrost documentation.
Evaluation and Testing: Where Maxim Excels
Evaluation approaches differ significantly between the platforms, reflecting their different target use cases.
Comprehensive Comparison
| Feature | Maxim | Braintrust |
|---|---|---|
| Multi-turn Agent Simulation | ✅ | ❌ |
| API Endpoint Testing | ✅ | ❌ |
| Agent Import via API | ✅ | ❌ |
| Human Annotation Queues | ✅ | ✅ |
| Third-party Human Evaluation Workflows | ✅ | ❌ |
| LLM-as-Judge Evaluators | ✅ | ✅ |
| Excel-Compatible Datasets | ✅ | ⛔️ (limited support) |
Multi-Turn Agent Simulation
Agent simulation represents one of Maxim's most significant differentiators. Rather than evaluating single LLM completions, teams can simulate complete conversational flows with realistic user personas.
Simulation capabilities enable:
- Testing agents across hundreds of scenarios without manual test case creation
- Validating conversational flows with multi-turn interactions
- Identifying failure modes in complex decision trees
- Reproducing issues found in production for systematic debugging
According to Maxim's simulation documentation, teams can configure maximum conversation turns, attach reference tools, and add context sources to enhance simulation realism.
API Endpoint Testing
Maxim enables direct testing of agents via API endpoints. Teams can import agents via API and run evaluations without instrumenting their entire codebase. This proves particularly valuable for:
- Evaluating agents built on no-code platforms
- Testing third-party AI services
- Validating agents across different tech stacks
- Rapid prototyping without deep SDK integration
Braintrust focuses on single-turn evaluations and lacks support for API endpoint testing, making it less suitable for teams with diverse agent architectures.
Third-Party Human Evaluation Workflows
While both platforms support human annotation queues, Maxim extends this with third-party human evaluation workflows. Teams can engage external annotators and subject matter experts to review agent outputs, critical for domains requiring specialized knowledge.
This capability supports comprehensive AI agent quality evaluation by combining automated metrics with human judgment at scale.
Dataset Flexibility
Maxim provides full support for Excel-compatible datasets, simplifying data import and export workflows. Braintrust offers limited support, potentially creating friction for teams working with existing evaluation datasets in spreadsheet formats.
Prompt Management for Production Agents
Prompt management requirements differ significantly between simple prompt-based applications and complex agent systems.
Feature Breakdown
| Feature | Maxim | Braintrust |
|---|---|---|
| Prompt CMS & Versioning | ✅ | ✅ |
| Visual Prompt Chain Editor | ✅ | ❌ |
| Side-by-side Prompt Comparison | ✅ | ✅ |
| Context Source via API / Files | ✅ | ❌ |
| Sandboxed Tool Testing | ✅ | ❌ |
Agent-Style Chains and Branching
Maxim's prompt tooling supports agent-style chains and branching through a visual prompt chain editor. This capability proves essential for teams building multi-step agents where different conversation paths require different prompting strategies.
The visual editor enables:
- Designing complex agent workflows without writing code
- Testing different branching logic based on user input
- Iterating on prompt strategies across conversation states
- Visualizing agent decision trees for debugging
Braintrust takes a more minimal approach, suited for developers managing prompts in code. Teams comfortable with code-first workflows may find this sufficient, but cross-functional teams benefit from Maxim's visual tools.
Context Sources and Tool Testing
Maxim supports context sources via API and files, allowing teams to enrich prompts with dynamic information from databases, APIs, and external systems. The sandboxed tool testing environment enables validation of tool calls before production deployment.
For comprehensive prompt engineering strategies, see the guide on prompt management in 2025.
Enterprise Readiness and Compliance
Enterprise deployments require robust security, compliance, and access control features. The platforms differ significantly in their enterprise readiness.
Enterprise Feature Comparison
| Feature | Maxim | Braintrust |
|---|---|---|
| SOC2 / ISO27001 / HIPAA / GDPR | ✅ All | ✅ SOC2 only |
| Fine-Grained RBAC | ✅ | ✅ |
| SAML / SSO | ✅ | ✅ |
| 2FA | ✅ All plans | ✅ |
| Self-Hosting | ✅ | ✅ |
Comprehensive Compliance Coverage
Maxim is designed for security-sensitive teams with comprehensive compliance certifications including SOC2, ISO27001, HIPAA, and GDPR. This breadth of coverage makes Maxim suitable for healthcare, financial services, and other highly regulated industries.
Braintrust offers SOC2 compliance but lacks the additional certifications that enterprises in regulated industries often require. Teams in healthcare dealing with protected health information (PHI) or those subject to GDPR requirements need platforms that explicitly support these standards.
Access Control and Authentication
Both platforms provide fine-grained role-based access control (RBAC), SAML/SSO integration, and two-factor authentication. Maxim offers 2FA on all plans, ensuring security is accessible to teams of all sizes.
In-VPC/Self-Hosting Options
Both Maxim and Braintrust support in-VPC/self-hosting for teams that prefer running tools internally with full control over deployment. Maxim provides comprehensive self-hosting documentation for enterprise deployments.
Maxim's security posture and trust center provide transparency into security practices, audit reports, and compliance documentation.
Pricing: Seat-Based vs Usage-Based Models
Pricing models significantly impact total cost of ownership, particularly as teams scale.
Pricing Structure Comparison
| Metric | Maxim | Braintrust |
|---|---|---|
| Free Tier | Up to 10k requests (logs & traces) | Up to 1M trace spans |
| Usage-Based Pricing | Professional: $1/10k logs, up to 100k logs & traces, 10 datasets (1000 entries each) | Pro: $249/mo (5GB processed, $3/GB thereafter; 50k scores, $1.50/1k thereafter; 1-month retention; Unlimited users) |
| Seat-Based Pricing | $29/seat/month (Professional), $49/seat/month (Business) | ❌ No seat-based pricing |
Maxim's Seat-Based Advantage
Maxim offers a seat-based pricing model where usage (up to 100k logs and traces) is bundled into the $29/seat/month Professional Plan. This provides predictable costs and granular access control, ideal for teams needing cost certainty.
Benefits of seat-based pricing:
- Predictable monthly costs regardless of usage spikes
- Natural alignment with team size and access requirements
- Included usage allowance sufficient for most development workflows
- Clear cost structure for budgeting and forecasting
Braintrust's Usage Model
Braintrust's flat $249/month Pro Plan includes unlimited users but quickly escalates costs with per-GB and per-metric overages. While the unlimited users feature appears attractive, teams with high-volume production systems may find costs unpredictable.
Cost escalation factors:
- $3 per GB beyond initial 5GB processed
- $1.50 per 1,000 scores beyond initial 50k
- 1-month retention may require additional spend for longer-term analysis
For high-volume, multi-user environments, Maxim's seat-based model typically proves more cost-efficient and predictable. See detailed pricing information for specific team requirements.
Real-World Impact: Thoughtful's Journey
Thoughtful's case study demonstrates the practical benefits of Maxim's approach to AI quality.
Key Outcomes
Cross-Functional Empowerment
Maxim enabled product managers to iterate directly and deploy updates to production without engineering involvement. This autonomy accelerated iteration cycles and reduced bottlenecks in the development process.
Streamlined Prompt Management
Thoughtful streamlined prompt management through Maxim's intuitive folder structure, version control, and dataset storage system. The organizational capabilities allowed the team to manage complex prompt hierarchies across multiple use cases.
Quality Improvement
Maxim reduced errors and improved response consistency by allowing Thoughtful to test prompts against large datasets before deployment. This pre-production validation caught issues early, preventing user-facing problems.
Broader Implications
The Thoughtful case study illustrates how comprehensive platforms enable cross-functional collaboration. Product managers participating directly in the AI quality process accelerates development while maintaining rigorous quality standards.
Additional case studies demonstrate similar benefits:
- Clinc improved conversational banking AI confidence
- Comm100 shipped exceptional AI support at scale
- Mindtickle implemented comprehensive quality evaluation
- Atomicwork scaled enterprise support with consistent AI quality
When to Choose Which Platform
The choice between Maxim and Braintrust depends on your specific use case and team requirements.
Choose Maxim If You're:
- Deploying agent-based workflows in production that require multi-turn conversations and complex decision trees
- Building with cross-functional teams where product managers and QA engineers need direct involvement without engineering bottlenecks
- Requiring detailed tracing and simulation with node-level visibility for debugging complex agent architectures
- Testing diverse agent architectures via HTTP endpoints without deep SDK instrumentation
- Needing enterprise-grade evaluation tooling and compliance (HIPAA, GDPR, ISO27001) for regulated industries
- Working with multiple technology stacks and need SDKs in Python, Go, TypeScript, or Java
- Seeking predictable costs through seat-based pricing for high-volume environments
- Requiring human-in-the-loop evaluation with third-party subject matter experts
Choose Braintrust If You're:
- Building prompt-based applications focused on RAG and single-turn interactions
- Preferring to self-host with full control over deployment
- Needing lightweight evaluation with rapid iteration on prompts
- Primarily engineering-driven with less need for cross-functional collaboration tools
- Working with lower volumes where usage-based pricing remains economical
- Comfortable with Python-only SDK and code-first workflows
Additional Platform Comparisons
For teams evaluating multiple platforms, consider these additional comparisons:
For broader context on AI evaluation approaches, explore:
Conclusion
Both Maxim and Braintrust offer strong foundations for AI quality, but they target different needs in the LLM lifecycle. Braintrust excels at evaluation and prompt testing for RAG and prompt-first applications, providing developers with rapid iteration capabilities and LLM-as-a-judge evaluation.
Maxim provides a comprehensive end-to-end platform for teams building production-ready agents. The key differentiators include:
- Multi-turn agent simulation for testing conversational flows across hundreds of scenarios with realistic user personas
- HTTP endpoint testing for evaluating agents programmatically without deep SDK instrumentation
- Superior developer experience with SDKs in Python, Go, TypeScript, and Java
- Cross-functional collaboration enabling product managers and QA engineers to contribute directly without engineering bottlenecks
- Node-level tracing for debugging complex agent workflows with granular visibility
- Third-party human evaluation workflows for comprehensive quality assessment with domain experts
- Comprehensive enterprise compliance (SOC2, HIPAA, GDPR, ISO27001) for regulated industries
- Flexible pricing with seat-based options for cost predictability in high-volume environments
Teams building agent-based systems benefit from Maxim's integrated approach spanning experimentation, simulation, evaluation, and observability. The platform's support for cross-functional collaboration enables product managers and QA engineers to contribute directly to AI quality, accelerating development cycles while maintaining rigorous standards.
For organizations deploying AI in regulated industries or those requiring detailed tracing and human-in-the-loop workflows, Maxim's comprehensive feature set and enterprise readiness make it the natural choice.
Ready to see how Maxim can transform your AI development workflow? Schedule a demo to discuss your specific requirements, or get started free to explore the platform's capabilities.
Additional Resources


