Hallucination Evaluation Frameworks: Technical Comparison for Production AI Systems (2025)

TL;DR
Hallucination evaluation frameworks help teams quantify and reduce false outputs in LLMs. In 2025, production-grade setups combine offline suites, simulation testing, and continuous observability with multi-level tracing. Maxim AI offers end-to-end coverage across prompt experimentation, agent simulation, unified evaluations (LLM-as-a-judge, statistical, programmatic), and distributed tracing with auto-eval pipelines. Alternatives—Arize, LangSmith, Langfuse, Galileo, span monitoring, chain introspection, and data-centric workflows.
Hallucination Evaluation: Engineering Requirements for 2025
Hallucinations represent a critical failure mode for LLM applications in production, particularly in retrieval-augmented generation (RAG) architectures, agentic workflows, and voice-based interfaces. Recent research establishes that hallucinations may be an intrinsic property of autoregressive language models trained on next-token prediction objectives. Production AI teams operationalize evaluation across three architectural layers:
- Pre-deployment test suites: Controlled evaluation against curated datasets with ground truth labels
- Simulation environments: Multi-turn conversational trajectories with persona-based user models to reproduce edge cases
- Production observability: Continuous auto-evaluation on live traffic with distributed tracing and alert pipelines
This layered approach aligns with emerging best practices for trustworthy AI deployment in enterprise contexts.
Key Evaluation Signals
- Faithfulness/Groundedness: Claims supported by retrieved context (essential for RAG systems)
- Context metrics: Relevance, precision@k, recall@k, nDCG for retrieval quality
- Task completion: Success rates for multi-step agentic workflows
- Tool selection accuracy: Correct function calls in agent trajectories
- Safety constraints: Toxicity, PII leakage, policy violations
Operational Infrastructure Requirements
- Distributed tracing: Span-level instrumentation across LLM calls, retrievals, and tool invocations
- Dataset management: Version-controlled test sets with production log sampling
- Prompt versioning: Git-style diffs, deployment variables, A/B testing infrastructure
- Automated quality gates: CI/CD integration with regression detection
- Human-in-the-loop workflows: Annotation interfaces for edge case curation
Measurable Outcomes
- Reduced production regression rates through pre-deployment quality gates
- Faster root-cause analysis via granular trace inspection
- Quantifiable improvements in grounding and task success metrics
Maxim AI: End-to-End Platform for Simulation, Evaluation, and Observability
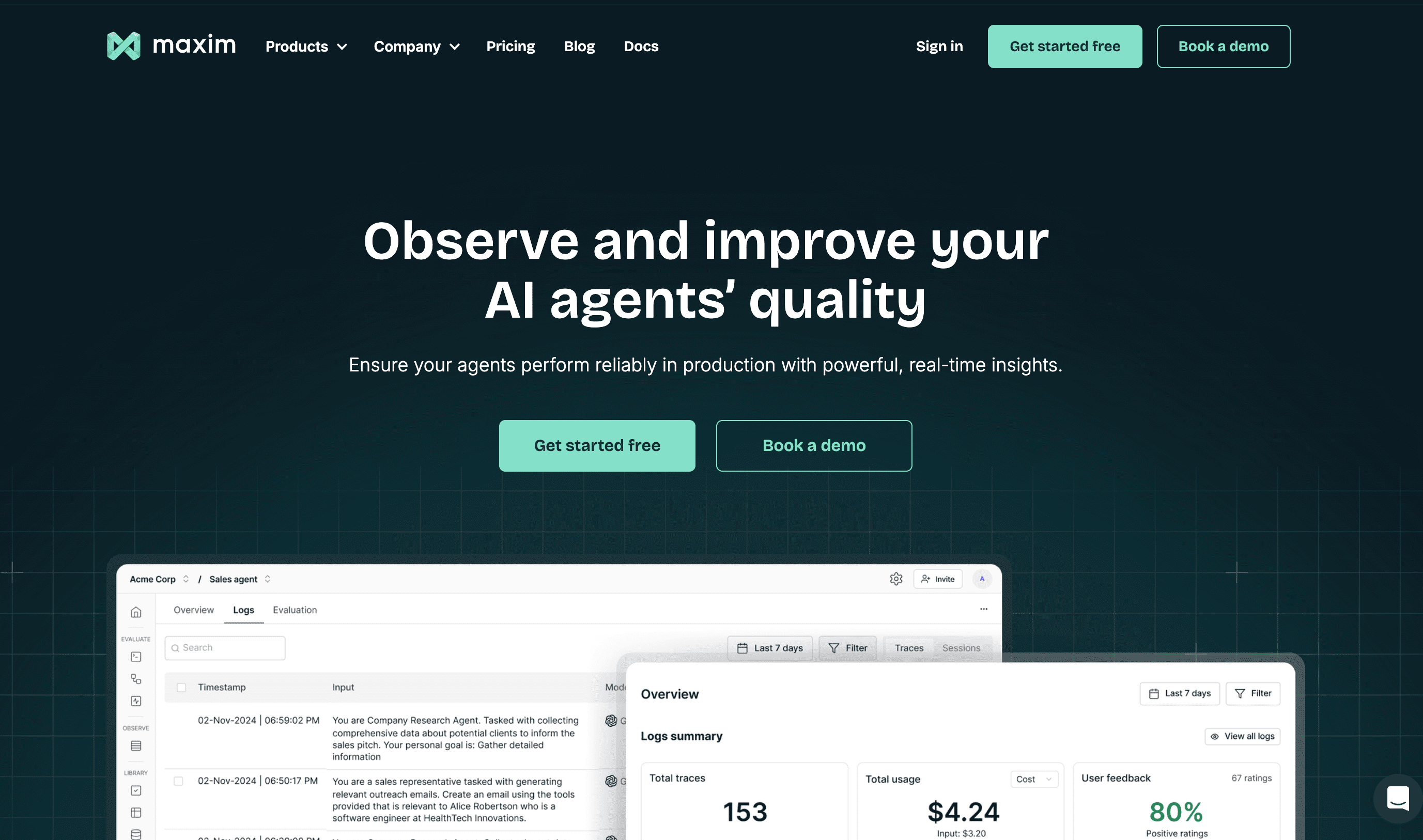
Platform Overview: Maxim AI is a unified platform for AI experimentation, simulation, evaluation, and observability designed to accelerate reliable AI agent development. The platform addresses the complete development lifecycle from prompt engineering through production monitoring.
Core Capabilities for Hallucination Mitigation
- Experimentation and prompt engineering with versioning, deployment variables, and comparative analysis of quality, cost, and latency. Experimentation product
- Simulation for multi-step conversational trajectories and re-runs from any step to reproduce issues—critical for investigating hallucinations in agent flows. Agent Simulation & Evaluation
- Unified evaluation framework that supports AI evaluators (LLM-as-a-judge), statistical evaluators (e.g., F1, BLEU, ROUGE), and programmatic checks; configurable at session, trace, or span level. Pre-built evaluators overview
- Observability with distributed tracing, auto-evaluations on logs, alerts/notifications, and datasets curated from production for ongoing quality improvement. Agent Observability
- Prompt management including versions, sessions, tool-calls, MCP, retrieval, and optimization—useful for reducing hallucinations through controlled iteration. Prompt Management docs
Target Use Cases
- End-to-end AI quality workflows: Teams requiring integrated experimentation, evaluation, and observability
- Cross-functional collaboration: SDK and UI-driven workflows for AI engineers and product teams
- Multi-level debugging: Precise hallucination isolation via session/trace/span granularity
- Continuous quality improvement: Human-in-the-loop annotation integrated with production logs
Technical Differentiators
- Granular trace instrumentation: Multi-level evaluation across sessions, traces, spans, generations, and tool calls
- Comprehensive evaluator coverage: AI, statistical, and programmatic evaluators with custom extension support
- Simulation-first approach: Reproduce complex conversational flows to isolate failure modes
- Automated quality gates: CI/CD integration with test runs via SDK
Evaluators relevant to hallucination reduction:
- Faithfulness (grounding to source), context relevance, context precision/recall, summarization quality, task success, step utility, step completion rules, tool selection checks, PII/toxicity safeguards.
- Statistical metrics for text similarity and correctness, plus programmatic validators for structured outputs.
- See evaluator store for complete list. Evaluator store
Best for:
- Teams needing full-stack AI quality: offline experimentation, scenario simulation, robust evaluator coverage, and live production observability.
- Cross-functional collaboration between AI engineers and product teams with both SDK and UI-driven workflows.
Highlights:
Multi-level tracing and evals across session, trace, and span enable precise isolation of hallucination root causes, while human-in-the-loop evaluation and dataset curation integrated with production logs streamline continuous quality improvement; together with a flexible evaluator library, custom dashboards, and alerts, these capabilities provide measurable, repeatable quality gates for deployment.
Arize: Enterprise Model Observability and Drift Detection
Platform Overview: Arize specializes in model observability and performance monitoring for ML and LLM systems in production. The platform focuses on detecting drift, performance degradation, and failure patterns at enterprise scale.
Core Features for Hallucination Evaluation
- Production monitoring dashboards: Real-time visibility into model behavior and quality metrics
- Tracing-style insights: Inspection of LLM application flows and component interactions
- Embedding-based analytics: Semantic drift detection and similarity checks for retrieval systems
- Enterprise governance: Compliance-ready observability with audit trails
Target Use Cases
- Organizations prioritizing production monitoring with established MLOps infrastructure
- Teams requiring enterprise-grade observability for model portfolio management
- Semantic analytics for RAG system performance tracking
Strengths
- Strong heritage in ML model monitoring and explainability
- Useful for detecting distribution shifts that correlate with hallucination rate increases
- Comprehensive embedding space analysis for retrieval quality assessment
LangSmith: LangChain-Native Experimentation and Tracing
Platform Overview: LangSmith provides tracing, evaluation, and debugging tooling optimized for LangChain-based applications. The platform offers deep integration with LangChain primitives and workflows.
Core Features for Hallucination Evaluation
- Chain-level trace visualization: Step-by-step inspection of chains, agents, tool calls, and prompts
- Evaluation runs on datasets: Test suite execution with custom metrics and LLM-as-a-judge patterns
- Collaboration features: Shared runs, version comparison, and team access controls
- Dataset management: Curation and versioning for test data
Target Use Cases
- Teams deeply invested in LangChain seeking first-class observability and evaluation
- Chain-centric application architectures requiring component-level debugging
Strengths
- Clear step-level introspection for pinpointing hallucination emergence in complex chains
- Native integration with LangChain's composable primitives
- Dataset-driven testing for reproducible assessments
Langfuse: Open-Source Observability with Self-Hosting Options

Platform Overview: Langfuse is an open-source observability platform for LLM applications providing logging, tracing, analytics, and evaluation capabilities with self-hosting support.
Core Features for Hallucination Evaluation
- Logging and tracing: Comprehensive capture of prompts, generations, and tool calls
- Evaluation hooks: Score outputs with custom metrics and LLM-as-a-judge evaluators
- Open-source flexibility: Vendor-neutral infrastructure with self-hosting options
- Analytics dashboards: Aggregated metrics and score visualization
Target Use Cases
- Engineering teams preferring self-hosted observability with open-source extensibility
- Organizations with strict data residency or governance requirements
Strengths
- Transparent data ownership and customizable evaluation pipelines
- Useful for compliance contexts requiring in-house data control
- Baseline hallucination tracking via trace analytics and score aggregation
Galileo: Data-Centric Quality Workflows and Human Review
Platform Overview: Galileo offers AI quality tooling with a data-centric approach, emphasizing dataset curation, evaluation, and iterative improvement workflows.
Core Features for Hallucination Evaluation
- Evaluation frameworks: Qualitative and quantitative assessment of LLM outputs
- Data curation workflows: Targeted dataset refinement based on failure analysis
- Collaboration tools: Review interfaces for stakeholder alignment and issue triage
- Quality metrics: Comprehensive scoring across multiple dimensions
Target Use Cases
- Product and AI teams focusing on dataset-driven quality improvements
- Human-in-the-loop workflows for addressing hallucinations through review processes
Strengths
- Emphasis on actionable data workflows and review loops for last-mile quality
- Complements observability platforms by strengthening evaluation-driven remediation
- Intuitive interfaces for non-technical stakeholders
Operational Playbook: Metrics, Workflows, and Instrumentation
Core Metrics for Hallucination Detection
Faithfulness and Grounding
- Definition: Proportion of claims in generated output supported by retrieved context
- Calculation: Statement-level entailment checking via LLM-as-a-judge or NLI models
- Scope: Essential for RAG systems and knowledge-grounded applications
- Maxim Implementation: Faithfulness evaluator
Context Quality Metrics
- Context Relevance: Alignment between retrieved documents and input query
- Context Recall: Proportion of answer-bearing information successfully retrieved
- Context Precision: Ranking quality (relevant documents precede irrelevant ones)
- Maxim Implementation: Context evaluator suite
Task-Level Metrics
- Task Success Rate: Goal completion in agentic workflows
- Step Completion: Correctness of intermediate reasoning steps
- Tool Selection Accuracy: Function call validation (correct tool + parameters)
- Maxim Implementation: Agent trajectory evaluators
Statistical Baselines
- Semantic Similarity: Embedding-based comparison (cosine, Euclidean distance)
- N-gram Overlap: BLEU, ROUGE-1/2/L for surface-level alignment
- F1/Precision/Recall: Token-level correctness when ground truth is available
- Maxim Implementation: Statistical evaluator library
Safety and Compliance
- PII Detection: Sensitive information leakage
- Toxicity Scores: Harmful content generation
- Format Validation: Schema compliance for structured outputs
- Maxim Implementation: Programmatic evaluators
Evaluation Workflows
Offline Evaluation (Pre-Deployment)
- Dataset construction: Curate test sets from production logs, edge cases, and synthetic generation
- Evaluation suite definition: Configure multi-metric evaluation with appropriate thresholds
- Comparative analysis: A/B test prompt variants, models, and retrieval strategies
- Quality gates: Block deployments failing minimum thresholds
Documentation: Offline Evaluations
Simulation-Based Testing
- Scenario design: Define persona-based conversational flows targeting known failure modes
- Multi-turn execution: Run stateful dialogues with context accumulation
- Trajectory analysis: Inspect step-by-step reasoning to isolate hallucination triggers
- Reproducibility: Re-run from arbitrary steps to validate fixes
Documentation: Text Simulation
Online Evaluation (Production)
- Auto-evaluation pipelines: Run configured evaluators on sampled production traffic
- Alert configuration: Trigger notifications on metric degradation or anomalies
- Dataset curation: Sample failing cases into test sets for offline analysis
- Continuous improvement: Iterate prompts/models based on production feedback
Documentation: Online Evaluations | Auto-evaluation setup
Distributed Tracing for Root-Cause Analysis
Effective hallucination debugging requires granular instrumentation:
- Session-level: User conversation threads with multi-turn context
- Trace-level: Complete request flows (query → retrieval → generation → response)
- Span-level: Individual operations (LLM calls, database queries, tool invocations)
- Generation-level: Model outputs with token probabilities and sampling parameters
- Retrieval-level: Retrieved documents with relevance scores
Documentation: Tracing Concepts | Tool Calls | Sessions
Conclusion: Production Hallucination Mitigation in 2025
Effective hallucination evaluation in 2025 demands architectural integration across three layers:
- Offline evaluation: Comprehensive test suites with multi-metric coverage (faithfulness, context quality, task success)
- Simulation: Stateful conversational flows to reproduce non-deterministic failures
- Production observability: Auto-evaluation pipelines with distributed tracing and alerting
Platforms differentiate on coverage breadth (experimentation, simulation, observability), evaluator depth (AI, statistical, programmatic), and instrumentation granularity (session/trace/span).
Maxim AI's integrated approach—unified prompt management, simulation environments, comprehensive evaluator library, and granular observability provides the most complete lifecycle support for building trustworthy AI. Combine evaluator breadth with trace depth and gateway-level governance (via Bifrost) to sustainably reduce hallucinations in RAG, copilot, and voice agent applications.
Next Steps
- Explore Maxim's platform: Products
- Review evaluator options: Evaluator Library
- Request a demo: Maxim Demo
- Sign up: Maxim Platform


