Human Annotations for Strong AI Evaluation Pipelines

Building reliable AI applications requires more than automated testing. While AI evaluation metrics provide speed and scalability, human annotations remain essential for capturing quality signals that automated systems cannot fully measure. This blog explains how human annotations integrate into evaluation pipelines, why they matter for AI quality assurance, and how combining them with automated evaluations creates a robust experimentation framework in Maxim AI.
Why Human Annotations Are Critical for AI Quality
Human annotations serve as ground truth for AI evaluation pipelines. Research from Stanford's Human-Centered AI institute demonstrates that human judgment remains essential for assessing subjective dimensions like helpfulness, safety, and alignment with user expectations, qualities that automated metrics frequently miss or misrepresent.
When evaluating conversational agents, voice agents, or retrieval-augmented generation systems, automated evaluators can measure latency, token consumption, and pattern matching. However, they struggle with context-dependent assessments. Does the agent demonstrate appropriate empathy? Is the tone suitable for the business context? Did the agent handle the conversation flow effectively? These questions require human judgment.
Human annotations provide three critical functions:
Validation of Automated Systems: Annotations validate whether automated evaluations align with actual user experience and business requirements. This validation proves particularly important during initial setup of AI monitoring systems where automated evaluators need calibration.
Training Signal for LLM-as-a-Judge: High-quality human annotations create datasets that train and refine LLM-based evaluators, improving their accuracy over time. Research from Anthropic on Constitutional AI demonstrates that human feedback significantly improves model alignment and evaluation quality.
Edge Case Identification: Human reviewers identify failure modes and edge cases that automated systems miss, enabling teams to expand test coverage and improve agent robustness. According to a study from Google Research on conversational AI, human annotations are particularly valuable for discovering unexpected system behaviors.

The Role of Human Annotations Across the AI Lifecycle
Human annotations integrate into three distinct phases of AI application development, each serving different objectives within the evaluation pipeline.
Pre-Production Evaluation
During development, engineering and product teams use annotations to establish quality baselines and validate improvements. Teams curate representative test datasets using Maxim's Data Engine, then systematically annotate outputs to understand current performance levels.
This phase focuses on building evaluation rubrics that reflect business objectives. Product managers can define annotation schemas that capture domain-specific quality dimensions without requiring engineering support. For customer service applications, this might include separate annotations for accuracy, empathy, policy compliance, and resolution effectiveness.
Production Monitoring
Once AI applications deploy to production, AI observability enables continuous quality oversight. Teams sample production logs for human review, creating a feedback loop that validates automated evaluations against real user interactions.
Production annotations serve multiple purposes. They identify quality regressions, uncover new user patterns, and provide ongoing validation that automated evaluators remain calibrated. Teams configure custom dashboards to surface high-priority interactions for review based on automated signals like low confidence scores or specific failure patterns.
Continuous Improvement
Annotated production data feeds back into experimentation pipelines, creating systematic improvement cycles. Teams use annotations to build regression test suites, ensuring future updates maintain quality on previously identified issues. The Playground enables rapid iteration on prompts while tracking how changes impact human-evaluated quality metrics.
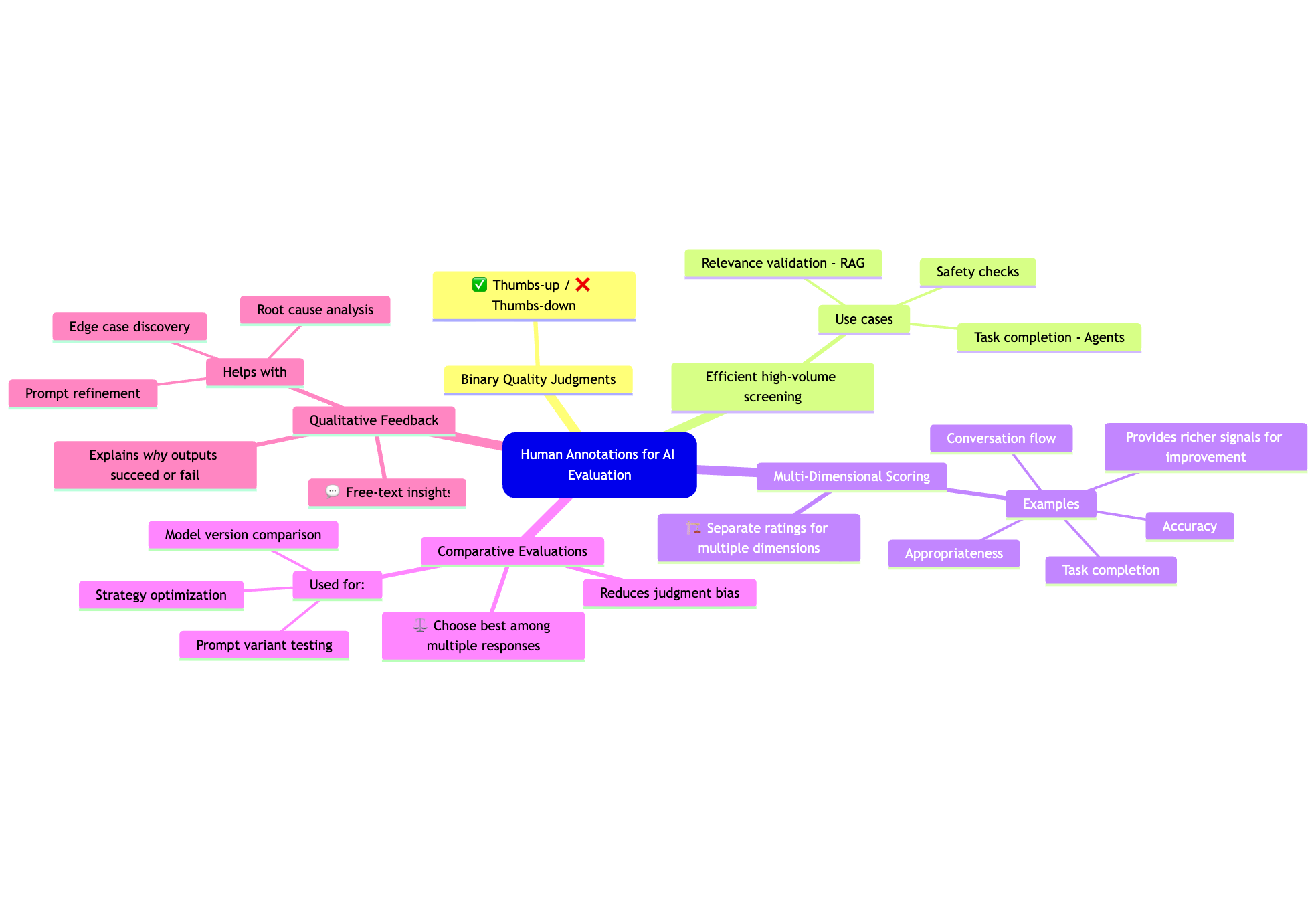
Types of Human Annotations for AI Evaluation
Different evaluation objectives require different annotation strategies. Maxim supports various annotation types to address diverse quality dimensions across AI applications.
Binary Quality Judgments
Binary annotations provide efficient thumbs-up or thumbs-down feedback on AI outputs. This approach works well for high-volume screening where reviewers need to quickly classify acceptable versus unacceptable responses. Binary annotations prove particularly effective for safety screening to flag potentially harmful content, relevance checking for RAG systems, and task completion verification for agent evaluation.
Multi-Dimensional Scoring
Complex AI applications require assessment across multiple quality dimensions. Multi-dimensional scoring allows annotators to rate different aspects of agent performance independently. For instance, evaluating a voice agent might include separate scores for accuracy, response appropriateness, conversation flow, and task completion.
Research on evaluation of dialogue systems demonstrates that multi-dimensional ratings provide richer signals than single overall scores, enabling more targeted improvements.
Comparative Evaluations
Comparative annotations ask human reviewers to select the superior output when comparing multiple agent responses. This approach proves valuable when establishing preferences between model versions, prompt variations, or agent strategies. Comparative evaluation reduces absolute judgment bias and provides clearer signals for model selection decisions.
Qualitative Feedback
While structured annotations provide quantitative metrics, free-text feedback captures qualitative insights about why certain outputs succeed or fail. Annotators describe edge cases, suggest improvements, and identify patterns that automated systems miss. This feedback proves invaluable during root cause analysis and prompt engineering iterations.
Integrating Annotations with Maxim's Evaluation Framework
Maxim AI provides comprehensive support for human annotations integrated with automated evaluation capabilities. This integration enables teams to build systematic quality assurance processes across the AI development lifecycle.
Data Management and Annotation Workflows
The Data Engine facilitates annotation workflows by enabling teams to import multi-modal datasets including text, images, and audio. Teams create custom annotation schemas tailored to their use case, whether evaluating customer service chatbots, voice agents, or specialized copilots.
Datasets in Maxim maintain version control, allowing teams to track annotation evolution over time. This versioning proves essential when annotation criteria change or when comparing model performance across different evaluation periods.
Combining Human and Automated Evaluations
The most effective AI evaluation strategy combines human annotations with automated evaluations in a complementary manner. Maxim's unified evaluation framework supports this hybrid approach through flexible evaluator configuration.
Automated Evaluators as First-Pass Filters: Configure automated evaluators at the session, trace, or span level to process every interaction in real-time. These evaluators include deterministic rules checking for policy violations, statistical evaluators measuring response characteristics, and LLM-as-a-judge evaluators assessing semantic quality. Automated evaluations flag suspicious interactions for human review, dramatically reducing annotation burden while maintaining comprehensive coverage.
Human Annotations for Calibration: Use human annotations on representative samples to establish ground truth. Compare automated evaluation results against human annotations to measure evaluator accuracy and identify systematic biases. Regular human annotation of production samples validates that automated evaluators remain accurate as user patterns evolve.
Iterative Evaluator Improvement: Human annotations provide training data for LLM-based evaluators. By annotating diverse examples with detailed quality assessments, teams create datasets that improve LLM judge accuracy through better prompting or fine-tuning. Research on training language models as reward models shows this approach significantly improves evaluation quality.

Building a Systematic Annotation Workflow
Implementing effective annotation workflows requires thoughtful process design. The following framework maximizes annotation value while minimizing cost and effort.
Establish Clear Annotation Guidelines
Define detailed guidelines specifying what annotators should evaluate and how to score each dimension. Guidelines should include concrete examples of excellent, acceptable, and poor outputs for each quality dimension. Clear guidelines reduce annotator disagreement and improve consistency. Research on annotation quality in natural language processing demonstrates that detailed guidelines significantly improve inter-annotator agreement.
Implement Stratified Sampling
For production annotation, use stratified sampling strategies that capture diverse interaction types. Random sampling alone may miss rare but important edge cases. Consider stratifying by conversation length, confidence scores, user demographics, or specific agent behaviors. Maxim's observability dashboards help identify these stratification criteria through custom views of production data.
Track Inter-Annotator Agreement
Regularly measure inter-annotator agreement to ensure consistency. When multiple annotators rate identical examples, scores should align within acceptable tolerances. Low agreement indicates unclear guidelines or insufficient training. Calculate Cohen's kappa or Fleiss' kappa to quantify agreement levels and identify areas requiring guideline refinement.
Create Annotation-Driven Experiments
Use annotations to drive systematic experimentation. The workflow follows these steps:
Baseline Establishment: Annotate a curated test set to establish baseline performance across relevant quality dimensions. The Data Engine enables versioning of these test sets for tracking changes over time.
Hypothesis Formation: Based on annotation insights, formulate hypotheses about potential improvements. These might involve prompt engineering, model selection changes, retrieval strategy modifications, or workflow adjustments.
Comparative Testing: Run experiments using the Playground to compare baseline against proposed changes. Human annotators evaluate outputs from both versions, providing comparative judgments that indicate whether changes improve quality.
Regression Testing: Before deployment, run comprehensive regression tests using both automated evaluators and human annotations. This ensures improvements in targeted areas do not cause degradation elsewhere. Maxim's evaluation framework enables tracking metrics across multiple dimensions simultaneously.
Production Validation: After deployment, continue human annotation of production samples to validate that improvements observed in testing translate to real user interactions. Configure alerts to trigger when quality metrics deviate from expected ranges.
Best Practices for Annotation-Driven Evaluation
Several best practices maximize the value of human annotations within evaluation pipelines:
Balance Cost and Coverage: Human annotation requires significant resources. Focus annotation effort where it matters most, novel scenarios, high-stakes interactions, and validation of automated evaluations. Use automated evaluations for broad coverage and reserve human review for strategic samples.
Maintain Annotation History: Track annotation history to identify quality trends over time and understand how user expectations evolve. The Data Engine maintains comprehensive version control enabling analysis of how annotation patterns change, informing updates to evaluation criteria.
Enable Cross-Functional Collaboration: Design annotation workflows that enable both technical and non-technical team members to contribute. Product managers, QA engineers, and customer support teams often provide valuable perspectives on AI quality that engineering teams might miss.
Use Progressive Disclosure: Structure annotation tasks using progressive disclosure. Start with high-level judgments before diving into detailed ratings. This approach accelerates annotation while ensuring detailed effort focuses on the most relevant examples.
Close the Feedback Loop: Ensure annotation insights feed back into development processes. Novel user queries become test cases, newly discovered failures inform prompt updates, and emerging patterns guide strategic improvements. This closed-loop process ensures evaluation remains grounded in actual user experience.
Conclusion
Human annotations remain essential for building reliable AI applications despite advances in automated evaluation. By integrating human judgment systematically into evaluation pipelines, teams capture nuanced quality signals, validate automated systems, and drive continuous improvement through structured experimentation.
Maxim AI provides end-to-end support for annotation-driven evaluation across the AI lifecycle, from pre-production testing through production monitoring to continuous refinement. The platform's unified approach to evaluation, observability, and data management enables teams to build robust quality assurance processes that combine human expertise with automated scale.
The most successful AI teams treat human annotations not as a one-time exercise but as an ongoing investment in quality assurance and continuous learning. This human-in-the-loop approach ensures AI applications remain aligned with user needs and business objectives as they evolve.
Ready to build stronger evaluation pipelines with integrated human annotations? Schedule a demo to see how Maxim AI accelerates your AI development workflow, or sign up to start improving your AI quality today.


