LLM as a Judge: A Practical, Reliable Path to Evaluating AI Systems at Scale

AI evaluation has shifted from static correctness checks to dynamic, context-aware judgment. As applications evolve beyond single-turn prompts into complex agents, tool use, and multi-step workflows, teams need evaluation that mirrors how users actually experience AI. Enter “LLM as a Judge” — using a model to evaluate other models or agents. When designed well, it brings speed, repeatability, and scale to a problem that used to rely entirely on expensive and inconsistent human reviews.
In this article, we cover how LLM-as-a-judge works, where it shines, where it fails, and how to operationalize it using proven workflows. We will reference public benchmarks and research, and outline a production-ready approach that combines automated judgment with robust guardrails and human calibration. Along the way, we connect the dots to practical evaluation setups using Maxim, with links to deeper reading on evaluation metrics, observability, and reliability.
- If you are exploring how to evaluate agents, start with Maxim’s primer on AI Agent Quality Evaluation.
- For an overview of metric design, see AI Agent Evaluation Metrics.
- For end-to-end pipelines, read Evaluation Workflows for AI Agents.
- To know more about Maxim AI, scehdule a demo with us at Demo.
Why LLM as a Judge is needed now?
Traditional metrics struggle to capture nuance in open-ended outputs. For example, two answers can both be “correct” yet differ dramatically in quality, style, completeness, or safety. As model capabilities improved, community benchmarks embraced human preference data and qualitative judgments as these often are able to capture these nuances that quantitative metrics fail to account for.
Two developments made LLM-as-a-judge compelling:
- Better models for evaluative reasoning. Modern models can follow rubrics, score outputs, and justify decisions across domains such as summarization, reasoning, coding, and dialogue.
- Operational pressure. Teams need faster feedback loops to ship improvements weekly or daily, not quarterly. Automated judges, properly designed, enable quick A/B testing, continuous integration checks, and production monitoring of qualitative behavior.
If you are building agents, you likely need evaluation that is iterative, task-specific, and outcome-focused. LLM-as-a-judge fits this need, particularly when backed by clear rubrics and cross-checked against human ground truth.
For a framework on how to structure evaluation scopes and granularity, see Maxim’s guide on Evaluation Workflows.
What does “LLM as a Judge” actually mean?
At its core, LLM-as-a-judge is a controlled prompt where a judge model:
- Receives the task context and candidate outputs.
- Applies a rubric that defines what “good” looks like.
- Produces a score or preference, often with a short rationale.
Common patterns:
- Pairwise preference: Compare Output A vs Output B and pick a winner with justification. This powers leaderboard-style comparisons and A/B tests.
- Pointwise scoring: Assign a numeric score on dimensions like correctness, completeness, usefulness, safety, and style.
- Rubric-based grading: Use a structured rubric with weighted criteria and compute an aggregate score.
- Reference-based checks: Compare to a known-good reference answer when available, allowing partial credit.
- Task-specific judges: Purpose-built prompts for summarization, retrieval QA, code generation, or multi-step agent plans.
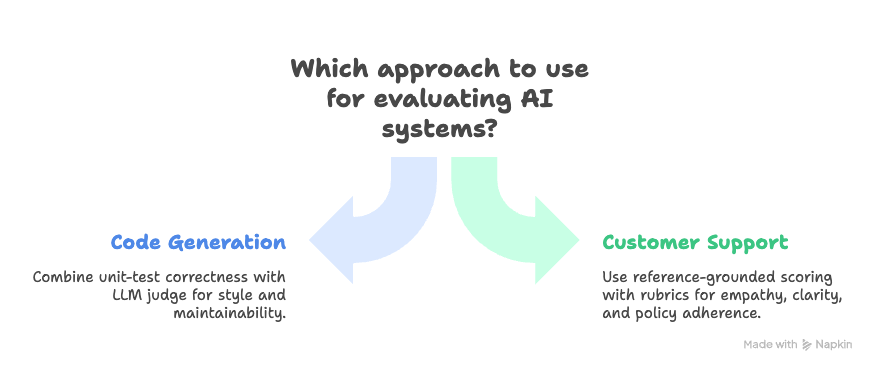
In practice, production teams blend these approaches depending on use case. For instance, code generation can combine unit-test correctness with an LLM judge that evaluates style and maintainability. Customer support agents may use reference-grounded scoring plus rubrics for empathy, clarity, and policy adherence.
For the taxonomy of metrics and how to pick them, see AI Agent Evaluation Metrics.
Benefits
- Speed at scale: You can evaluate thousands of samples in minutes, enabling rapid iteration and frequent releases.
- Consistency: A well-specified rubric reduces reviewer drift that plagues human-only evaluation.
- Explainability of decisions: Judges produce rationales, which help teams debug failures and refine prompts.
- Coverage of qualitative factors: Judges handle attributes like helpfulness, structure, and safety that are hard to express with purely quantitative metrics.
- Cost efficiency: Automated judgment reduces the marginal cost per evaluation and frees human reviewers for adjudication and calibration.
These strengths are particularly impactful in agent systems where multi-turn reasoning and tool calls create complex outputs.
Limitations and risks
LLM-as-a-judge is not a silver bullet. Known challenges include:
- Bias and position effects: Judges may prefer longer answers, certain styles, or the first presented output if prompts are not balanced.
- Model identity bias: Judges can favor outputs from models similar to themselves.
- Overfitting to rubric phrasing: Small wording changes can shift scores.
- Hallucinated rationales: Explanations can be plausible but incorrect.
- Domain brittleness: Judges can underperform on specialized or compliance-heavy tasks without domain-specific rubrics and examples.
To mitigate these risks, teams should run human calibration studies, randomize output order, use multi-judge committees, and compute agreement metrics.
A practical checklist for reliability and governance is outlined in AI Reliability: How to Build Trustworthy AI Systems, alongside LLM Observability and Model Monitoring.
How the community has used LLM judges
Public benchmarks and evaluations have helped standardize patterns:
- MT-Bench and Chatbot Arena popularized automated preference judgments and pairwise comparisons for dialogue models, with carefully designed prompts and community review. See the MT-Bench introduction from LMSYS and their overview of Arena-style comparisons.
- OpenAI’s open-source evaluation efforts made it easier to operationalize automated checks across tasks and datasets, encouraging the use of rubric-driven judgments and human validation loops.
These examples highlight a few hard-earned lessons: keep rubrics crisp, randomize order, measure agreement, and periodically refresh test data to avoid overfitting.
If you are comparing frameworks to run and analyze evaluations, this short overview of Maxim vs LangSmith and Maxim vs Langfuse clarifies differences in scope and focus.
Designing a good judge rubric
Rubric design is the single most important factor in LLM-as-a-judge quality. A useful rubric:
- Declares the goal in plain language.
- Enumerates criteria that matter for the task.
- Specifies weights per criterion and a total scoring range.
- Provides short positive and negative examples.
- Constrains the judge’s output format to reduce drift.
For example, a short-answer QA rubric might include:
- Correctness and factual grounding: Is the answer accurate and supported by context or citations when required.
- Completeness: Does it address all parts of the question succinctly.
- Clarity: Is the language direct and unambiguous.
- Safety and policy: Does it avoid prohibited content and follow domain constraints.
Rubrics can be reference-based (when you have gold answers) or reference-free (when only expected behavior is known). Many teams start reference-free to gain broad coverage, then introduce reference-based checks for high-stakes tasks.
For a practical approach to structuring rubrics into metrics and workflows, read Evaluation Workflows for AI Agents.
Choosing the judge model
Factors that influence judge performance:
- Capability level: Stronger models generally produce more stable, discriminative judgments.
- Domain alignment: For legal, medical, or financial tasks, use a model and context tuned to domain rules.
- Cost and latency: Consider batch size, parallelism, and caching.
- Transparency and logging: Ensure you can trace judge rationales, inputs, and outputs for auditing.
- Robustness: Prefer models that can follow constrained output formats and handle adversarial or low-quality inputs without collapsing.
Maxim’s evaluation stack is model-agnostic, which makes it straightforward to compare judges and measure agreement across them. You can then standardize on a primary judge and retain backups for drift detection.
Explore how teams structure this in How to Ensure Reliability of AI Applications.
Evaluation modes: pairwise, pointwise, and rubric-driven
- Pairwise comparisons
Ideal for A/B testing models or prompts. The judge sees both outputs and a task context, then picks a winner with rationale. Strong for ranking and leaderboard updates. - Pointwise scoring
Good for regression tracking. Assign a scalar or vector of scores per output, which you can aggregate across datasets for release gating. Works well when you have stable rubrics. - Rubric-driven grading
Combine multiple dimensions and weights. For agents, use separate rubrics at the turn level (tool selection, grounding) and task level (final outcome, policy adherence). See examples of metric decomposition in AI Agent Evaluation Metrics.
Teams commonly mix modes. For example, pairwise for rapid model comparisons, pointwise for CI checks, and rubric-driven grades for release decisions.
Agreement, calibration, and gold sets
Automated judges must be calibrated against human ground truth:
- Gold sets: Curate a small, high-quality human-labeled dataset for periodic calibration and drift checks.
- Agreement metrics: Compute inter-annotator agreement and judge-human agreement using statistics like percent agreement, Cohen’s kappa, or Krippendorff’s alpha.
- Threshold selection: Use ROC analysis when converting judge scores to pass or fail gates.
- Bias probes: Include synthetic probes that detect verbosity preference, position bias, and style sensitivity.
Calibration does not have to be expensive. Even a few hundred well-annotated samples, refreshed quarterly, can materially improve trust in automated judges. A deeper view of evaluation discipline is in What Are AI Evals and Maxim’s AI Reliability guide.
Making judges robust
Judges can be gamed if prompts leak rubrics or if systems optimize directly against their quirks. To harden judges:
- Hide rubrics from the task model to reduce overfitting.
- Rotate judge prompts and templates.
- Randomize output order in pairwise prompts.
- Use multi-judge committees and majority voting or median scoring.
- Add adversarial reviewers that look for unsupported claims, irrelevant verbosity, or policy violations.
- Enforce constrained output formats for judges to reduce variance.
- Periodically switch judge models or versions and measure agreement before and after.
Applying LLM-as-a-judge to agents
Agent evaluation requires both micro and macro lenses:
- Micro level: Did the agent pick the right tool, parse its response correctly, retry sensibly, and follow policy at each step.
- Macro level: Did it solve the task with acceptable tradeoffs in latency, cost, and safety.
A practical agent evaluation plan includes:
- Scenario coverage: Synthetic and real conversations, edge cases, and negative controls.
- Step-level traces: Capture thoughts, tool calls, and intermediate outputs for downstream judging.
- Outcome checks: Grounded correctness, policy adherence, and user satisfaction proxies.
- Safety reviews: Model content controls and domain-specific rules.
For a detailed blueprint, see Evaluation Workflows for AI Agents and the distinction explained in Agent Evaluation vs Model Evaluation. For hands-on debugging techniques, see Agent Tracing for Debugging Multi-Agent AI Systems.
Building a production-ready llm-as-a-judge evaluator with Maxim
Here is a pragmatic approach to implement LLM-as-a-judge using Maxim’s evaluation stack:
- Define goals and scope
- Choose your target behaviors: correctness, usefulness, safety, style, or task completion.
- Map to metrics: binary gates, scalar scores, or pairwise preferences. Reference AI Agent Evaluation Metrics.
- Author rubrics and templates
- Create concise rubrics, one per task family.
- Provide one to two examples per criterion.
- Constrain the judge response format.
- Learn prompt organization best practices from Prompt Management in 2025.
- Assemble datasets and scenarios
- Collect historical logs and user journeys.
- Add synthetic cases for hard negatives and edge behaviors.
- Version datasets for reproducibility, as discussed in What Are AI Evals.
- Choose judge models
- Select the llm model.
- Consider context window and cost.
- Consider fine-tuned models for certain tasks.
- Implement evaluation workflows
- Orchestrate pairwise, pointwise, and rubric-driven evaluations across datasets.
- Persist traces and rationales for audit.
- See the end-to-end pattern in Evaluation Workflows for AI Agents.
- Calibrate and gate releases
- Compare judge output with human gold sets.
- Compute agreement and select thresholds that align with risk tolerance.
- Use pass gates in CI to prevent regressions. Guidance in How to Ensure Reliability of AI Applications.
- Monitor in production
- Track evals scores post-deploy for drift and regressions.
- Alert on safety violations and severe quality drops.
- Build dashboards with dimensions by model version, prompt, user segment, and scenario. See LLM Observability and Model Monitoring.
- Continuously improve
- Add new scenarios, refresh gold sets, and rotate judges.
- Feed failures back into prompt tuning.
- Conduct periodic audits for bias and fairness.
- Explore Maxim’s case studies for practical patterns when scaling: Clinc, Comm100, and Mindtickle.
If you want an overview of how Maxim compares to broader MLOps observability and evaluation tools, see Maxim vs Comet and Maxim vs Arize.
Metrics that matter
Beyond average evals scores, track metrics that reflect business risk and user experience:
- Agreement with humans: Use agreement coefficients on your gold sets.
- Coverage: Percentage of critical scenarios and policies tested each release.
- Win rate: Pairwise preference win rate for new versions over baselines.
- Safety violation rate: Rate of flagged responses per thousand interactions.
- Latency and cost: End-to-end runtime and per-eval spend.
- Drift: Changes in average scores or distribution shifts by segment.
Tie these to operational gates: for example, require minimum win rate and safety compliance before production rollout. For a more comprehensive treatment, revisit AI Agent Evaluation Metrics.
Handling safety and compliance
Judges are especially useful for safety and policy adherence, where rules can be encoded in rubric checks:
- Content safety: Disallow harmful categories.
- Privacy: Detect PII exposure or data leakage.
- Brand and tone: Enforce stylistic and voice guidelines.
- Domain policy: Apply sector-specific rules for finance, healthcare, or legal contexts.
To avoid false confidence, pair automated checks with human escalation for borderline cases and measure false positive and false negative rates during calibration. Additional practices are summarized in AI Reliability.
Common failure modes and how to mitigate them
- Position bias in pairwise prompts
Mitigation: Randomize order and average across multiple prompt templates. - Verbosity and stylistic bias
Mitigation: Penalize unnecessary length and explicitly reward concision in rubrics. - Identity bias
Mitigation: Hide model identity in prompts. Use different model families in the judge ensemble. - Overfitting to the judge
Mitigation: Rotate judges, change prompt seeds, and validate against human gold sets before deployment. - Hallucinated rationales
Mitigation: Require explicit evidence in rationales or use constrained formats with references to context. - Domain brittleness
Mitigation: Provide domain exemplars in the rubric and fine-tune or select a domain-aware model as a judge.
End-to-end example: Evaluating a support agent
Imagine a customer support agent that handles billing questions:
- Dataset: Real anonymized transcripts plus synthetic variations.
- Rubric: Correctness, policy adherence, empathy, and next-step clarity.
- Judge prompt: Reference grounding to knowledge base snippets, require explicit citation where used.
- Metrics: Pass rate per criterion, aggregate score, and pairwise win rate vs prior model.
- Production: Monitor drift, alert on safety violations, and auto-roll back if pass rate falls below threshold.
See related patterns in Shipping Exceptional AI Support Inside Comm100’s Workflow and Scaling Enterprise Support: Atomicwork’s Journey.
Advanced techniques: Committees, adversaries, and meta-evaluation
Once the basics are solid, advanced strategies improve robustness:
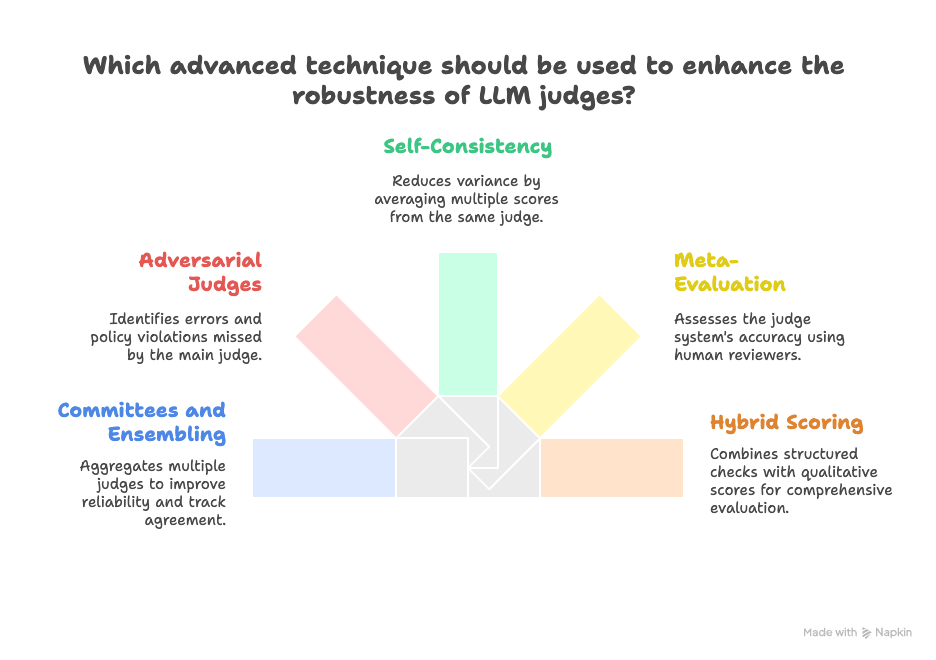
- Committees and ensembling
Use multiple judges with different prompts or models. Aggregate using majority vote or rank aggregation for pairwise comparisons. Track inter-judge agreement as a health signal. - Adversarial judges
Add a specialized reviewer to search for logical errors, unsupported claims, or policy violations even when the main judge passes an output. - Self-consistency
Ask judges to score multiple times with slight paraphrases and average results to reduce variance. - Meta-evaluation
Periodically evaluate your judge system itself using human reviewers on a stratified sample. Compute the rate at which judges agree with humans and investigate discrepancies. - Hybrid scoring
Combine structured checks such as exactness, unit tests, or retrieval grounding with qualitative judge scores, then weight them according to business priorities.
For a procedural view of how these techniques fit into day-to-day workflows, revisit Evaluation Workflows for AI Agents.
How Maxim fits into LLM-as-a-judge
Maxim focuses on evaluation and reliability for AI agents and applications. Teams use it to:
- Organize prompts, datasets, rubrics, and judges in one place. See guidance in Prompt Management in 2025.
- Run repeatable evaluation workflows across pairwise, pointwise, and rubric-driven modes.
- Trace agent steps and judge rationales for debugging, described in Agent Tracing.
- Monitor eval scores in production with alerts, dashboards, and drift detection, as covered in LLM Observability and Model Monitoring.
- Govern releases with pass gates tied to metrics that matter to your product and compliance risk, synthesized in How to Ensure Reliability of AI Applications.
If you are comparing frameworks, see competitor comparisons like Maxim vs LangSmith and Maxim vs Langfuse, or request a walkthrough at the demo page.
Practical checklist
- Define business goals for evaluation and map them to metrics.
- Write task-specific rubrics with examples and weights.
- Choose capable judge models and measure agreement.
- Build datasets that cover common paths, edge cases, and safety.
- Mix pairwise, pointwise, and rubric-driven modes.
- Calibrate with human gold sets and track agreement.
- Harden judges with randomization, committees, and adversarial prompts.
- Monitor in production and refresh datasets regularly.
- Review bias and fairness quarterly, rotate judges as needed.
- Document changes and version everything for reproducibility.
Conclusion
LLM-as-a-judge is a pragmatic response to the scale and complexity of modern AI systems. It turns qualitative evaluation into a disciplined, repeatable process. The key is not the idea itself but its execution: clear rubrics, robust prompts, calibrated judges, and production-grade monitoring. When implemented with care, automated judges accelerate iteration without compromising trust.
Whether you are tuning a prompt, upgrading a model, or rolling out an agent to thousands of users, the combination of rubric design, multi-mode evaluation, and continuous monitoring forms the backbone of reliable AI. If you want to explore a production-ready approach, start with the resources below and see how teams operationalize these patterns with Maxim.


