

The 5 Leading Platforms for AI Agent Evals in 2025

The shift from static LLM applications to autonomous AI agents has transformed how organizations approach quality assurance. Traditional model evaluation frameworks that assess single-turn text generation are insufficient for systems that make multi-step decisions, call external tools, and adapt their behavior across complex interaction sequences. Research from IBM on AI agent evaluation confirms that evaluating agents requires assessment beyond surface-level text quality to include task success, reasoning trajectories, and alignment with user intent.
According to Google's analysis of agent evaluation challenges, comprehensive agent assessment must examine both final outputs and the decision-making processes that produced them. Organizations deploying AI agents in production environments face unique requirements for simulation capabilities, trajectory-level evaluations, multi-turn conversation testing, and continuous quality monitoring. The platforms examined in this guide represent the leading solutions for teams building reliable, production-grade AI agents at scale.
Table of Contents
- What Makes Agent Evaluation Different from Model Evaluation
- Core Requirements for Agent Evaluation Platforms
- Top 5 Platforms for AI Agent Evaluation
- Platform Comparison
- Agent Evaluation Workflow
- Implementation Best Practices
- Conclusion
What Makes Agent Evaluation Different from Model Evaluation
AI agents operate fundamentally differently from standalone language models. While model evaluation focuses on measuring output quality for specific prompts, agent evaluation must assess entire workflows including reasoning chains, tool selection accuracy, error recovery mechanisms, and multi-turn conversational coherence.
Key distinctions:
- Task completion vs output quality: Agents must successfully complete complex tasks rather than simply generate coherent text
- Multi-step reasoning: Evaluation must trace decision-making across multiple intermediate steps
- Tool interaction assessment: Platforms must verify correct tool selection, parameter passing, and result interpretation
- Context maintenance: Multi-turn evaluations examine how agents maintain context across extended conversations
- Error handling: Robust evaluation frameworks test recovery from failures and unexpected scenarios
According to research on agentic systems, these requirements demand specialized platforms that integrate simulation capabilities, trajectory-level metrics, and production monitoring into unified workflows.
Core Requirements for Agent Evaluation Platforms
Organizations building production AI agents require platforms delivering specific capabilities across the development lifecycle. Based on analysis of enterprise evaluation needs, leading platforms must provide:
Simulation capabilities:
- Multi-turn conversation generation across diverse user personas
- Scenario-based testing covering edge cases and failure modes
- Scalable parallel execution across thousands of test cases
Evaluation frameworks:
- Pre-built evaluators for common agent metrics (task completion, tool accuracy, safety)
- Custom evaluator support for domain-specific requirements
- Human-in-the-loop workflows for subjective quality assessment
Observability infrastructure:
- Distributed tracing showing agent reasoning and tool calls
- Real-time monitoring of production agent behavior
- Performance dashboards tracking latency, cost, and quality metrics
Workflow integration:
- CI/CD pipeline integration for automated testing
- Dataset curation from production logs and synthetic generation
- Version control for prompts, agents, and evaluation configurations
Enterprise requirements:
- Role-based access control (RBAC) for cross-functional collaboration
- SOC 2 compliance and in-VPC deployment options
- SSO integration and secure API key management
Top 5 Platforms for AI Agent Evaluation
1. Maxim AI - Enterprise-Grade Agent Lifecycle Platform
Maxim AI delivers the most comprehensive solution for AI agent evaluation, integrating simulation, testing, and observability into a unified platform designed for enterprise deployment. Organizations, including Clinc, Thoughtful, and Comm100 rely on Maxim to ship reliable AI agents more than 5x faster through systematic evaluation workflows.
Agent Simulation at Scale
Maxim's simulation capabilities enable teams to test agents across thousands of realistic scenarios before production deployment:
- Multi-turn conversation simulation: Generate realistic user interactions spanning multiple exchanges, testing how agents maintain context and adapt responses across conversation flows
- Persona-based testing: Define custom user personas with specific goals, knowledge levels, and communication styles to evaluate agent performance across diverse user segments
- Scenario generation: Create comprehensive test suites covering common paths, edge cases, and failure scenarios using both synthetic data and production logs
- Parallel execution: Run thousands of simulations simultaneously, dramatically accelerating testing cycles and enabling rapid iteration
The platform supports testing across major agent frameworks including LangGraph, OpenAI Agents SDK, Crew AI, and others through native integrations. According to Maxim's documentation, teams can re-run simulations from any step to reproduce issues and validate fixes systematically.
Comprehensive Evaluation Framework
Maxim provides the industry's deepest evaluation capabilities through flexible frameworks supporting automated, statistical, and human assessment:
Pre-built evaluators:
- Task completion and goal achievement metrics
- Tool selection accuracy and parameter correctness
- Conversational coherence and context maintenance
- Safety evaluators for bias, toxicity, and harmful content
- RAG-specific metrics including retrieval precision, recall, and relevance
- Faithfulness and hallucination detection for factual accuracy
Custom evaluator support:
- Deterministic rule-based evaluators for precise business logic validation
- Statistical evaluators analyzing distribution patterns and anomalies
- LLM-as-a-judge implementations for nuanced quality assessment
- Programmatic evaluators integrating domain-specific validation logic
According to Maxim's evaluation documentation, teams configure evaluations at session, trace, or span level, providing granular quality control across multi-agent systems. This flexibility enables measurement at the conversation level, individual reasoning step level, or specific tool call level depending on analysis requirements.
Production Observability and Monitoring
Maxim's observability suite provides comprehensive visibility into production agent behavior through distributed tracing and real-time monitoring:
- Distributed tracing: Track agent execution across complex workflows with OpenTelemetry-compatible instrumentation, visualizing reasoning chains, tool calls, and inter-agent communication
- Real-time dashboards: Monitor critical metrics including latency, token consumption, cost per interaction, and quality scores across agent versions
- Automated quality checks: Run continuous evaluations on production traffic using sampling strategies, detecting degradation before significant user impact
- Custom alerting: Configure notifications when evaluation metrics fall below thresholds, costs exceed budgets, or latency degrades beyond acceptable ranges
- Trace debugging: Drill into specific agent interactions to examine decision-making processes, tool outputs, and context usage patterns
Research demonstrates that comprehensive observability reduces mean-time-to-resolution for production issues by enabling rapid identification of failure modes within complex agent workflows.
Experimentation and Prompt Management
The Playground++ environment enables rapid iteration on agent configurations without code changes:
- Visual prompt editor: Modify system prompts, user message templates, and tool descriptions through an intuitive interface accessible to non-technical team members
- Version control: Automatically track all prompt changes with metadata including author, timestamp, and change rationale for complete audit trails
- Side-by-side comparison: Evaluate different agent configurations simultaneously, comparing output quality, latency, and cost metrics across variations
- Deployment rules: Configure conditional logic determining which agent versions serve specific user segments, environments, or feature flags
- Tool definition management: Define, test, and iterate on agent tool interfaces and implementations within the experimentation framework
This decoupling of agent configuration from application code enables product teams to iterate on agent behavior independently, accelerating optimization cycles while maintaining engineering velocity.
Dataset Curation and Management
Maxim's data engine streamlines creation and maintenance of high-quality evaluation datasets:
- Multi-source ingestion: Import datasets from CSV files, production logs, synthetic generation, or manual creation
- Multimodal support: Handle text, images, audio, and structured data within unified dataset management workflows
- Continuous evolution: Curate datasets from production interactions, automatically identifying edge cases and failure modes for regression testing
- Human-in-the-loop labeling: Implement scalable annotation workflows with customizable review interfaces and quality control mechanisms
- Dataset versioning: Maintain complete history of dataset changes, enabling reproducible evaluations across development iterations
According to Maxim's simulation documentation, teams combine synthetic generation with production-derived examples to create comprehensive test suites reflecting real-world usage patterns.
CI/CD Integration and Automation
Maxim enables systematic quality gates through automated evaluation pipelines:
- SDK-first design: Trigger evaluations programmatically using Python, TypeScript, Java, or Go SDKs with minimal code overhead
- REST API access: Integrate evaluation workflows into any development pipeline through comprehensive API endpoints
- Automated regression detection: Run evaluation suites on every commit or deployment, comparing results against established baselines
- Quality thresholds: Configure pass/fail criteria preventing deployments when quality metrics fall below acceptable levels
- Report generation: Automatically generate evaluation summaries and share results with stakeholders through configurable notifications
This integration ensures teams maintain quality standards while shipping agent improvements continuously.
Enterprise Security and Governance
Maxim provides production-grade security features essential for regulated industries:
- SOC 2 Type 2 compliance: Certified security controls and comprehensive audit processes
- In-VPC deployment: Private cloud options maintaining data sovereignty and network isolation
- RBAC implementation: Granular permissions controlling access to experiments, datasets, evaluations, and production monitoring
- SSO integration: Enterprise authentication through Google, GitHub, and custom identity providers
- Vault support: Secure API key management via HashiCorp Vault integration
These capabilities enable cross-functional collaboration while maintaining security and compliance requirements for enterprise deployments.
Cross-Functional Collaboration
Maxim's interface enables seamless collaboration between AI engineers, product managers, and QA teams:
- No-code evaluation workflows: Product managers define and execute evaluation runs without engineering dependencies
- Shared dashboards: Cross-functional visibility into agent performance, evaluation results, and production metrics
- Annotation workflows: Subject matter experts provide quality feedback through intuitive labeling interfaces
- Comment and approval flows: Structured review processes ensure stakeholder alignment before production deployments
According to Maxim's platform overview, this collaboration model reduces bottlenecks while maintaining quality standards across the development lifecycle.
2. Langfuse - Open Source Observability Platform
Langfuse provides open source observability focused on prompt management and tracing for LLM applications. The platform captures detailed execution traces and supports prompt versioning through its interface.
Core capabilities:
- Detailed trace capture for agent execution paths
- Prompt versioning tied to performance metrics
- Cost and latency tracking per interaction
According to research on evaluation tools, Langfuse suits engineering teams requiring unified views of LLM systems, though evaluation and simulation capabilities are less comprehensive than full-stack platforms.
3. Arize Phoenix - ML Observability Focused
Arize Phoenix emphasizes observability and monitoring for machine learning and LLM applications, with support for embedding drift detection and performance tracing.
Notable features:
- Embedding drift detection across model versions
- Performance tracing for LLM interactions
- Post-deployment monitoring dashboards
Research indicates that Arize excels in production monitoring but requires integration with additional tooling for pre-production experimentation and comprehensive evaluation workflows.
4. LangSmith - LangChain Ecosystem Integration
LangSmith provides evaluation and debugging capabilities tightly integrated with the LangChain framework, offering native support for chain and agent workflows built using LangChain.
Key features:
- Native LangChain integration for chains and agents
- Execution trace visualization for debugging
- Evaluation pipelines for LangChain workflows
According to platform comparisons, LangSmith serves teams invested in LangChain ecosystems, though broader multi-framework support is limited.
DeepEval
Platform Overview
DeepEval is a Python-first LLM evaluation framework similar to Pytest but specialized for testing LLM outputs. DeepEval provides comprehensive RAG evaluation metrics alongside tools for unit testing, CI/CD integration, and component-level debugging.
Key Features
Comprehensive RAG Metrics: Includes answer relevancy, faithfulness, contextual precision, contextual recall, and contextual relevancy. Each metric outputs scores between 0-1 with configurable thresholds.
Component-Level Evaluation: Use the @observe decorator to trace and evaluate individual RAG components (retriever, reranker, generator) separately. This enables precise debugging when specific pipeline stages underperform.
CI/CD Integration: Built for testing workflows. Run evaluations automatically on pull requests, track performance across commits, and prevent quality regressions before deployment.
G-Eval Custom Metrics: Define custom evaluation criteria using natural language. G-Eval uses LLMs to assess outputs against your specific quality requirements with human-like accuracy.
Platform Comparison
| Feature | Maxim AI | Langfuse | Arize Phoenix | LangSmith | DeepEval |
|---|---|---|---|---|---|
| Multi-Turn Simulation | Comprehensive with personas | Limited | Limited | Via LangChain | Limited |
| Pre-Built Evaluators | Extensive (bias, toxicity, RAG, safety) | Basic | ML-focused | Chain-focused | Rich metric library |
| Custom Evaluators | Flexible (deterministic, statistical, LLM) | Supported | Programmatic | Chain-based | Python-defined metrics |
| Production Observability | Full distributed tracing | Trace capture | Strong monitoring | LangChain traces | Basic tracking |
| Human-in-the-Loop | Scalable workflows | Limited | Limited | Limited | Limited |
| CI/CD Integration | SDK + API native | Supported | Supported | Supported | Pytest / CI friendly |
| Cross-Functional UX | No-code workflows | Developer-focused | Developer-focused | Developer-focused | Developer-focused |
| Enterprise Security | SOC 2, in-VPC, RBAC | Open source | Enterprise available | Enterprise tier | Self-hosted option |
| Framework Support | Multi-framework | LangChain-focused | Multi-framework | LangChain native | Framework agnostic |
| Dataset Management | Comprehensive curation | Basic | Limited | Limited | Basic |
Agent Evaluation Workflow
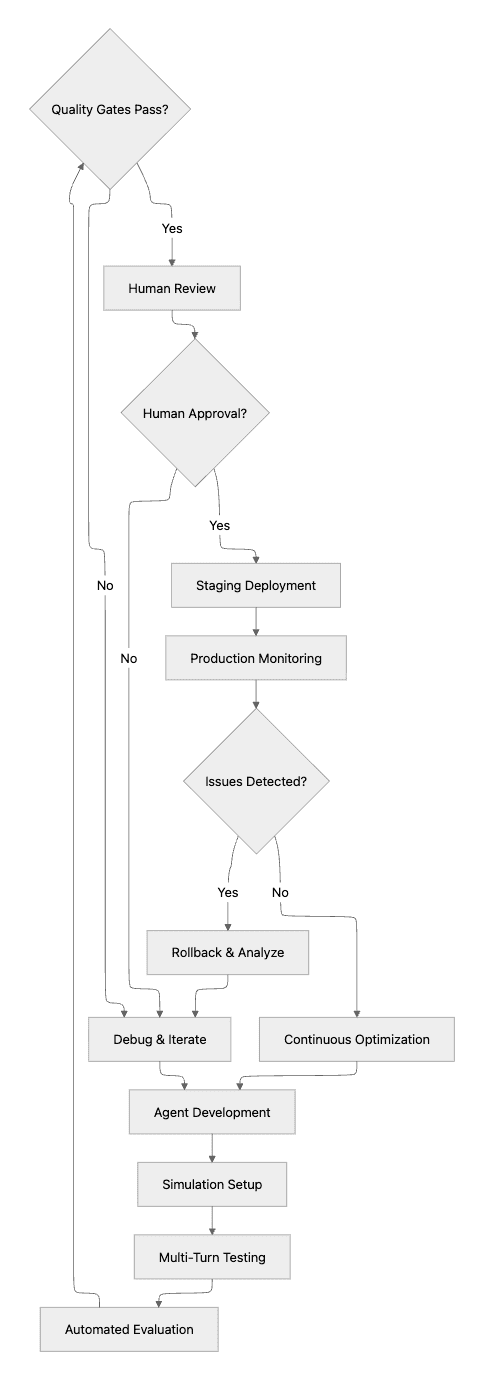
The workflow illustrates how comprehensive evaluation platforms enable systematic quality assurance from development through production monitoring, with feedback loops at each stage.
Implementation Best Practices
Based on research by AI engineering teams, implement these practices for reliable agent deployments:
1. Build Comprehensive Test Suites
Create evaluation datasets covering diverse scenarios:
- Common paths: Test typical user interactions and expected workflows
- Edge cases: Identify boundary conditions and unusual input patterns
- Failure scenarios: Verify graceful degradation when tools fail or contexts are ambiguous
- Adversarial inputs: Test robustness against prompt injection and manipulation attempts
Maxim's dataset curation enables continuous evolution of test suites from production logs and synthetic generation.
2. Implement Layered Evaluation
Assess agents at multiple granularity levels:
- Conversation-level metrics: Measure overall task completion, user satisfaction, and goal achievement
- Turn-level assessment: Evaluate individual response quality, appropriateness, and helpfulness
- Step-level analysis: Examine reasoning chains, tool selection accuracy, and parameter correctness
- Component evaluation: Test individual agent capabilities (reasoning, tool use, memory) independently
This layered approach, detailed in Maxim's evaluation framework, enables precise identification of failure modes within complex agent systems.
3. Combine Automated and Human Evaluation
Balance scalability with nuanced quality assessment:
- Automated evaluators: Run high-volume testing measuring quantifiable metrics (accuracy, latency, cost)
- LLM-as-a-judge: Assess subjective qualities (helpfulness, tone, appropriateness) at scale
- Human review: Validate edge cases, subjective judgments, and high-stakes interactions
- Continuous feedback: Use human annotations to improve automated evaluators over time
According to Maxim's platform documentation, this combination provides comprehensive quality assurance while maintaining practical evaluation velocity.
4. Monitor Production Continuously
Implement systematic observability for deployed agents:
- Sampling strategies: Evaluate representative subsets of production traffic to detect quality drift
- Real-time alerts: Configure notifications for metric degradation, cost overruns, or safety violations
- Trace analysis: Investigate user-reported issues through detailed execution traces
- Performance dashboards: Track key metrics across agent versions, user segments, and time periods
Maxim's observability suite enables teams to maintain quality standards while agents evolve through continuous improvement cycles.
5. Integrate Quality Gates
Embed evaluation into development workflows:
- Pre-commit testing: Run critical evaluation suites before code commits
- Staging validation: Execute comprehensive evaluations in staging environments
- Canary deployments: Gradually roll out changes while monitoring quality metrics
- Automated rollback: Revert deployments when quality thresholds are breached
This integration ensures teams maintain quality standards while shipping agent improvements continuously.
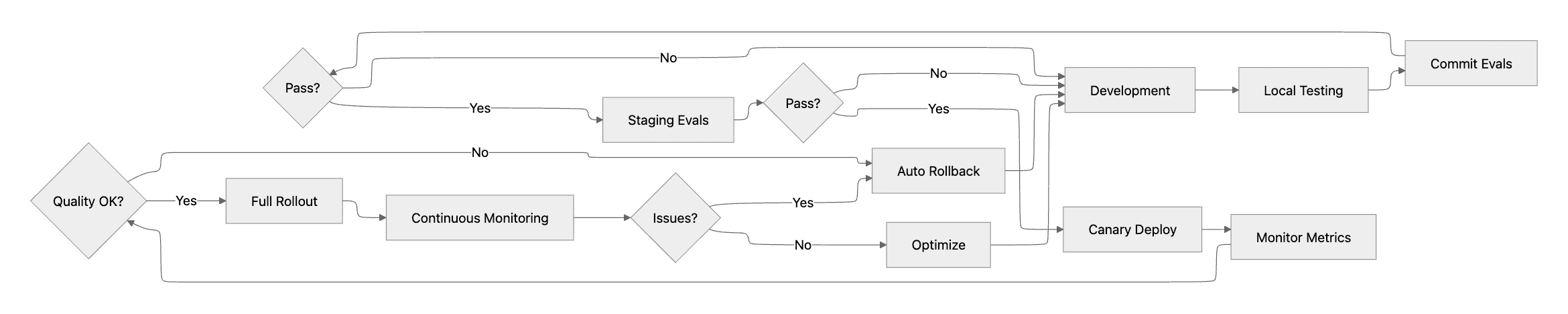
This deployment workflow demonstrates how systematic evaluation enables teams to maintain production quality while iterating rapidly on agent improvements.
Conclusion
AI agent evaluation requires specialized platforms that integrate simulation capabilities, comprehensive evaluation frameworks, and production observability into unified workflows. The non-deterministic nature of agent decision-making, combined with complex multi-step reasoning and tool interactions, demands systematic approaches going beyond traditional model evaluation.
Among the platforms examined, Maxim AI provides the most complete solution for organizations building production-grade AI agents. The platform uniquely delivers end-to-end lifecycle coverage integrating experimentation, simulation, evaluation, and observability. With enterprise-grade security, cross-functional collaboration features, and comprehensive evaluation frameworks supporting automated, statistical, and human assessment, Maxim enables AI teams to ship reliable agents more than 5x faster while maintaining quality standards.
For teams requiring specialized capabilities, Langfuse offers open source observability, Arize Phoenix provides ML-focused monitoring, LangSmith integrates tightly with LangChain workflows, and, DeepEvals delivers developer-focused GitHub integration. However, as research on enterprise evaluation requirements demonstrates, comprehensive platforms that unify simulation, evaluation, and monitoring deliver the greatest value for production AI deployments.
Ready to implement systematic agent evaluation for your AI applications? Book a demo to see how Maxim accelerates agent development while maintaining production quality, or sign up now to start evaluating agents systematically and shipping reliable AI systems at scale.


