Top 5 AI Evaluation Tools for Running AI Evals in Your CI/CD Pipeline in 2025

TL;DR: Modern AI development demands continuous quality validation through automated evaluations in CI/CD pipelines. Maxim AI leads with comprehensive GitHub Actions integration, end-to-end simulation capabilities, and flexible evaluation frameworks spanning experimentation, testing, and production monitoring. DeepEvals offer comprehensive RAG evaluation metrics. Promptfoo provides open-source security-focused evaluation. Langfuse delivers self-hostable observability with eval capabilities. Arize Phoenix brings OpenTelemetry-based monitoring. Each platform addresses different aspects of AI quality assurance, from rapid prototyping to enterprise-scale deployments.
Why CI/CD Integration Is Critical for AI Quality
The traditional software development approach of shipping code through automated testing pipelines has proven its value over decades. Teams deploying AI applications face an even greater challenge because AI behavior is probabilistic rather than deterministic. A prompt change, model swap, or parameter adjustment can silently degrade quality in ways that unit tests cannot catch.
Recent research on AI-augmented CI/CD pipelines shows that organizations implementing automated AI evaluations catch regressions before production deployment, maintain higher quality standards, and ship with confidence comparable to traditional software. The shift from manual testing to continuous evaluation represents a fundamental evolution in how teams build reliable AI systems.
Teams building production AI applications need infrastructure that validates quality dimensions like factuality, relevance, instruction following, and multi-turn task completion at every code change. These capabilities transform evaluation from a bottleneck into an accelerator, enabling rapid iteration while maintaining rigorous quality standards.
What Makes an Excellent AI Evaluation Tool for CI/CD?
Before examining specific platforms, consider the essential capabilities that differentiate basic testing tools from production-grade evaluation platforms:
Native CI/CD Integration: The best tools provide dedicated GitHub Actions or pre-built integrations for major CI/CD platforms rather than requiring custom scripts. Clean pull request commenting and automated experiment creation streamline developer workflows.
Comprehensive Evaluation Frameworks: Beyond simple pass/fail gates, platforms must support LLM-as-a-judge evaluators, retrieval quality metrics, custom scorers, and multi-agent evaluation capabilities. The ability to evaluate at different granularities (session, trace, span level) proves essential for complex systems.
Developer Experience: Local testing capabilities, watch modes for rapid iteration, and clear debugging interfaces reduce friction in the development cycle. Teams should be able to run evaluations locally before committing code.
Deployment Flexibility: Organizations with data residency requirements need self-hosting options, while fast-moving startups benefit from managed cloud deployments. The best platforms support both approaches.
Cross-Functional Collaboration: Modern AI development involves product managers, AI engineers, and QA teams. Platforms that enable seamless collaboration without requiring all stakeholders to write code accelerate development cycles.
1. Maxim AI (Most Comprehensive Full-Stack Platform)
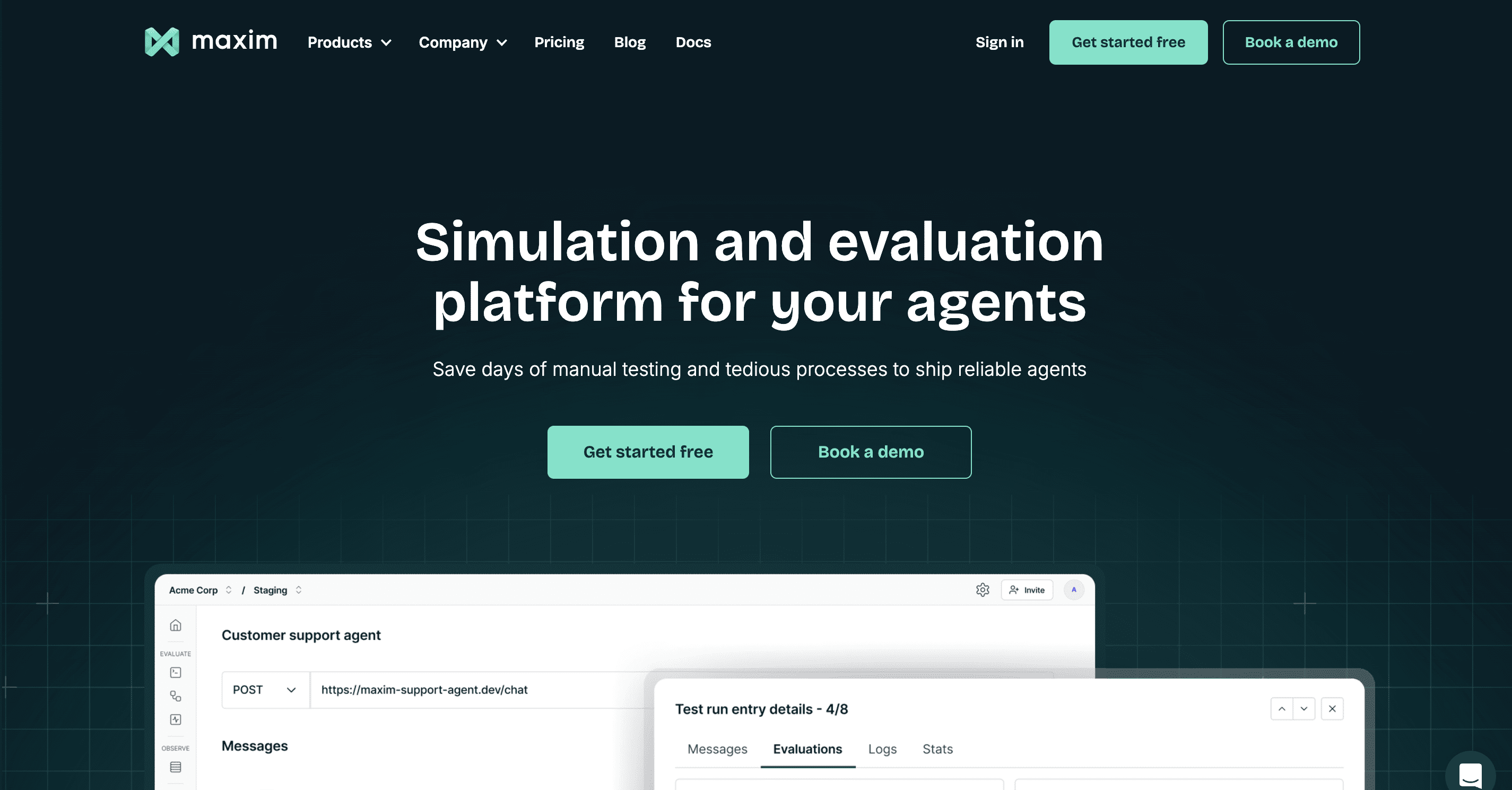
Maxim AI stands out as the only evaluation platform providing end-to-end capabilities spanning experimentation, simulation, evaluation, and observability. While competitors focus on specific phases of AI development, Maxim delivers a unified platform where teams can iterate in the experimentation playground, test through AI-powered simulations, validate with comprehensive evaluations, and monitor production performance through advanced observability.
GitHub Actions Integration That Works
Maxim provides native GitHub Actions integration through the maximhq/actions/test-runs@v1 action. Teams can configure automated prompt testing that runs on every push or pull request with minimal setup:
- name: Run Prompt Test with Maxim
uses: maximhq/actions/test-runs@v1
with:
api_key: ${{ secrets.MAXIM_API_KEY }}
workspace_id: ${{ vars.WORKSPACE_ID }}
dataset_id: ${{ vars.DATASET_ID }}
prompt_version_id: ${{ vars.PROMPT_VERSION_ID }}
evaluators: "bias, clarity, faithfulness"
This integration automatically posts detailed results to pull requests, including failed test indices and comprehensive reports. Unlike platforms requiring custom Python scripts, Maxim's action works out of the box and scales to enterprise workflows.
Simulation: The Game-Changer for Agent Testing
What truly differentiates Maxim is its agent simulation capabilities. Rather than testing agents with static datasets, teams can simulate realistic multi-turn conversations across hundreds of user personas and scenarios. This approach catches issues that single-shot evaluation misses, such as conversation derailments, tool usage failures, and task abandonment.
Companies like Comm100 use Maxim's simulation to test their AI-powered customer support agents across diverse scenarios before production deployment. Thoughtful leverages simulations to validate their healthcare revenue cycle automation agents against complex multi-step workflows.
Flexible Evaluation Framework
Maxim's evaluation system supports three evaluation types:
Deterministic Evaluators: JSON schema validation, PII redaction checks, latency thresholds, and cost budgets provide binary pass/fail gates for critical requirements.
Statistical Evaluators: Embedding similarity, BLEU scores, and statistical measures quantify output quality improvements across versions.
LLM-as-a-Judge: Pre-built evaluators for bias, clarity, faithfulness, relevance, and custom rubric-based assessments score outputs using language models. Teams can configure these at session, trace, or span level for granular quality measurement.
Unlike platforms requiring separate tools for different evaluation types, Maxim unifies all three approaches in a single framework. The evaluator store provides off-the-shelf evaluators while supporting fully custom implementations.
Production Observability and Continuous Improvement
Maxim's platform doesn't stop at pre-deployment testing. The observability suite enables teams to monitor production performance, run periodic quality checks, and curate datasets from production logs for continuous improvement.
Atomicwork's case study demonstrates this full-cycle approach. Their team uses Maxim to experiment with prompts, run extensive evaluations, monitor production quality, and feed real-world failures back into their test suites - creating a virtuous cycle of continuous quality improvement.
Data Curation and Human-in-the-Loop
Maxim's data engine facilitates importing datasets, enriching them through human review, and evolving them based on production insights. This human-in-the-loop capability proves essential for maintaining alignment with user preferences over time.
The platform supports custom dashboards that provide insights across multiple dimensions of agent behavior. Product teams can create these visualizations with clicks rather than code, democratizing access to quality insights across the organization.
Best For
Teams requiring comprehensive lifecycle coverage from experimentation through production, cross-functional collaboration between engineering and product teams, advanced simulation capabilities for multi-agent systems, and flexible self-hosted or cloud deployment options.
DeepEval
Platform Overview
DeepEval is a Python-first LLM evaluation framework similar to Pytest but specialized for testing LLM outputs. DeepEval provides comprehensive RAG evaluation metrics alongside tools for unit testing, CI/CD integration, and component-level debugging.
Key Features
Comprehensive RAG Metrics: Includes answer relevancy, faithfulness, contextual precision, contextual recall, and contextual relevancy. Each metric outputs scores between 0-1 with configurable thresholds.
Component-Level Evaluation: Use the @observe decorator to trace and evaluate individual RAG components (retriever, reranker, generator) separately. This enables precise debugging when specific pipeline stages underperform.
CI/CD Integration: Built for testing workflows. Run evaluations automatically on pull requests, track performance across commits, and prevent quality regressions before deployment.
G-Eval Custom Metrics: Define custom evaluation criteria using natural language. G-Eval uses LLMs to assess outputs against your specific quality requirements with human-like accuracy.
Confident AI Platform: Automatic integration with Confident AI for web-based result visualization, experiment tracking, and team collaboration.
3. Promptfoo
Promptfoo represents the open-source, security-first approach to AI evaluation. The platform provides comprehensive red teaming capabilities alongside standard evaluation features.
Configuration-Driven Approach
Teams define evaluation cases in YAML files that live alongside code, making evaluation maintenance straightforward. The configuration files support complex scenarios with multiple providers and custom evaluators.
CI/CD Support Across Platforms
Native support for GitHub Actions, GitLab CI, Jenkins, CircleCI, and more enables integration regardless of your CI/CD platform. Built-in caching and quality gate support streamline the evaluation process.
Security-First Design
Built-in red teaming for prompt injection, PII leaks, jailbreaks, and vulnerabilities differentiates Promptfoo from evaluation-only platforms. Teams can validate security posture alongside functional quality.
Limitations
Unlike cloud platforms, teams must manage infrastructure, store results, and maintain secrets themselves. There's no centralized experiment tracking or quality trend analysis across deployments. The YAML configuration can become complex for sophisticated evaluation scenarios.
Best For
Engineering teams prioritizing open-source solutions, organizations with stringent security requirements, and teams comfortable managing their own evaluation infrastructure.
4. Langfuse

Langfuse positions itself as an open-source LLM engineering platform with observability, prompt management, and evaluation capabilities. While it provides some evaluation features, CI/CD integration requires significant custom development.
Flexible Evaluation Approaches
Langfuse supports LLM-as-a-judge evaluators, human annotations, and custom scoring through APIs and SDKs. The platform enables multiple evaluation methodologies within a single system.
Self-Hosting Without Limits
All core features can be self-hosted for free without any limitations, appealing to organizations with data residency requirements or cost concerns.
GitHub Integration for Prompts
Webhook integration triggers workflows when prompts change, enabling some automation of the evaluation process.
Limitations
Langfuse lacks a native CI/CD action. Teams must write custom Python scripts to fetch traces, run evaluations, and save results. This manual orchestration significantly increases setup complexity compared to platforms with dedicated GitHub Actions.
Dataset experiments and production trace evaluations exist in separate platform areas, requiring context switching rather than unified experiment tracking. The evaluation workflow feels disconnected from the development cycle.
Best For
Teams wanting to self-host all capabilities, organizations building custom evaluation pipelines, and projects where observability takes priority over automated CI/CD testing.
5. Arize Phoenix
Arize Phoenix brings open-source observability built on OpenTelemetry standards. While primarily focused on monitoring, the platform includes evaluation capabilities that can integrate with CI/CD pipelines.
Built on Open Standards
Based on OpenTelemetry and OpenInference, Phoenix ensures instrumentation work remains reusable across platforms. Teams already invested in OpenTelemetry find integration straightforward.
Self-Hostable with Single Command
Deploy with a single Docker command for free with no feature gates or restrictions. The open-source model provides complete transparency and control.
Limitations
Phoenix requires writing custom code for CI/CD integration. Without a dedicated GitHub Action, teams must build workflows using the experiments API and Python scripts. This significantly increases setup complexity.
The evaluation features are less mature compared to dedicated evaluation platforms. While Phoenix provides comprehensive observability, the evaluation and experiment comparison interfaces feel secondary to the core monitoring capabilities.
Best For
Teams already using the Arize ecosystem, organizations prioritizing observability over evaluation, and projects where OpenTelemetry standardization matters more than turnkey CI/CD integration.
Comparison Table
| Tool | Starting Price | Best For | Key Differentiator |
|---|---|---|---|
| Maxim AI | Free tier available | Full lifecycle AI development | End-to-end platform with simulation, evaluation, and observability |
| DeepEval | Free (Open source) | Test-centric LLM evaluation | Pytest-style evaluation with reusable, code-first tests and metrics |
| Promptfoo | Free (Open source) | Security testing | Red teaming and vulnerability scanning built-in |
| Langfuse | Free (Self-hosted) | Custom workflows | Complete self-hosting freedom with flexible evaluation |
| Arize Phoenix | Free (Self-hosted) | OpenTelemetry users | Standards-based observability with evaluation capabilities |
Choosing the Right Platform for Your Team
The evaluation tool landscape in 2025 offers mature solutions addressing different development phases and team structures. Maxim AI leads with its comprehensive full-stack approach, providing capabilities from prompt experimentation through production monitoring in a unified platform.
Teams building complex multi-agent systems benefit most from Maxim's simulation capabilities, which test realistic scenarios that static datasets miss. The native GitHub Actions integration eliminates setup friction while providing detailed quality insights on every pull request.
For teams prioritizing experiment tracking with excellent developer experience, DeepEvals offer comprehensive RAG evaluation metrics. Promptfoo serves security-conscious teams comfortable managing open-source infrastructure. Langfuse and Phoenix suit organizations prioritizing self-hosting and observability over turnkey CI/CD integration.
When evaluating platforms, consider your specific requirements around:
Lifecycle Coverage: Do you need only evaluation, or would simulation and production monitoring provide value? Full-stack platforms accelerate development by eliminating integration overhead.
Team Collaboration: Can product managers and QA engineers participate directly, or does all quality work flow through engineering? Cross-functional platforms reduce bottlenecks.
Deployment Preferences: Cloud-hosted for rapid scaling or self-hosted for data control? The best platforms support both models with consistent features.
Integration Complexity: Native actions that work immediately or custom scripting required? Developer productivity compounds when tooling feels invisible.
Getting Started with CI/CD Evaluation
Implementing automated AI evaluation follows a systematic process regardless of platform choice:
Build Representative Datasets: Collect evaluation cases covering core scenarios, edge cases, and known failure modes. Source examples from production logs, user feedback, and synthetic generation.
Define Quality Metrics: Establish deterministic checks (schema validation, latency limits), statistical measures (embedding similarity, BLEU scores), and LLM-judge evaluators for subjective quality dimensions.
Set Thresholds and Gates: Define minimum scores, per-metric requirements, and aggregate rules that block deployment when violated. Start conservatively and refine based on false positive rates.
Integrate with Pipeline: Add evaluation to pull request workflows for rapid feedback. Supplement with comprehensive nightly runs against full test suites for regression detection.
Iterate Based on Results: When evaluations fail, investigate root causes, update prompts or logic, and add failure cases to test suites. This continuous improvement cycle maintains quality over time.
Teams using Maxim can accelerate this process through built-in workflows for data curation, evaluation configuration without code, and automated quality monitoring. The platform's end-to-end approach eliminates the tool switching that fragments evaluation workflows on other platforms.
The Future of AI Quality Assurance
The convergence of evaluation, simulation, and observability represents the next evolution in AI development infrastructure. Teams no longer accept siloed tools that force manual integration. The competitive advantage belongs to organizations that can iterate rapidly while maintaining rigorous quality standards.
Research on AI agent reliability shows that systematic evaluation catches issues orders of magnitude cheaper than production failures. Automated CI/CD testing transforms this insight into practice, making quality validation automatic rather than aspirational.
Ready to implement production-grade AI evaluation in your CI/CD pipeline? Schedule a demo to see how Maxim's full-stack platform accelerates development while ensuring quality, reliability, and trustworthiness across your AI applications. Start with our free tier to experience comprehensive evaluation, simulation, and observability without commitment.


