Top 5 Arize AI Alternatives, Compared (2026)

TL;DR
Looking for an Arize AI alternative? Here's the quick breakdown:
Maxim AI is the most comprehensive option, offering end-to-end simulation, evaluation, and observability with strong cross-functional collaboration between engineering and product teams. LangSmith excels for teams deeply embedded in the LangChain ecosystem. Langfuse provides open-source flexibility with full self-hosting control. Comet Opik provides LLM observability with broader ML workflows. Weights & Biases Weave works best for ML teams extending their existing W&B infrastructure to LLMs.
If you need a full-stack platform covering experimentation through production monitoring with both technical depth and product team accessibility, Maxim AI delivers the most complete solution.
Table of Contents
- Why Teams Are Looking Beyond Arize AI
- How to Evaluate AI Observability Platforms
- Maxim AI: Full-Stack AI Quality Platform
- LangSmith: LangChain Ecosystem Observability
- Langfuse: Open-Source LLM Engineering
- Comet Opik
- Weights & Biases Weave: ML Platform Extension
- Feature Comparison Matrix
- Decision Framework
- Further Reading
Why Teams Are Looking Beyond Arize AI
As AI agents become critical infrastructure for enterprises, choosing the right observability and evaluation platform determines whether your AI systems deliver reliable value or fail silently in production. While Arize AI has established itself in the ML observability space with its Phoenix open-source framework, many teams are discovering that modern agentic workflows demand more comprehensive solutions.
Arize AI built a solid foundation for ML observability, and their Phoenix framework has gained traction as an open-source LLM tracing tool. However, as AI applications evolve from simple prompt chains to complex multi-agent systems, teams encounter specific limitations:
- Traditional ML focus. Arize's core platform was designed for predictive ML models, including drift detection, feature monitoring, and model performance. LLM capabilities were added later, creating a somewhat fragmented experience.
- Limited pre-production testing. While Arize excels at production monitoring, it lacks robust simulation and experimentation capabilities for testing agents before deployment.
- Engineering-centric workflows. The platform primarily serves technical users, making it difficult for product teams to participate in AI quality workflows without engineering dependencies.
- Evaluation depth. The "council of judges" approach provides basic quality assessment, but teams building sophisticated agents often need more flexible, configurable evaluation frameworks.
How to Evaluate AI Observability Platforms
Before comparing specific alternatives, it helps to understand the key dimensions that differentiate AI observability platforms. The following diagram illustrates the core capabilities to assess:
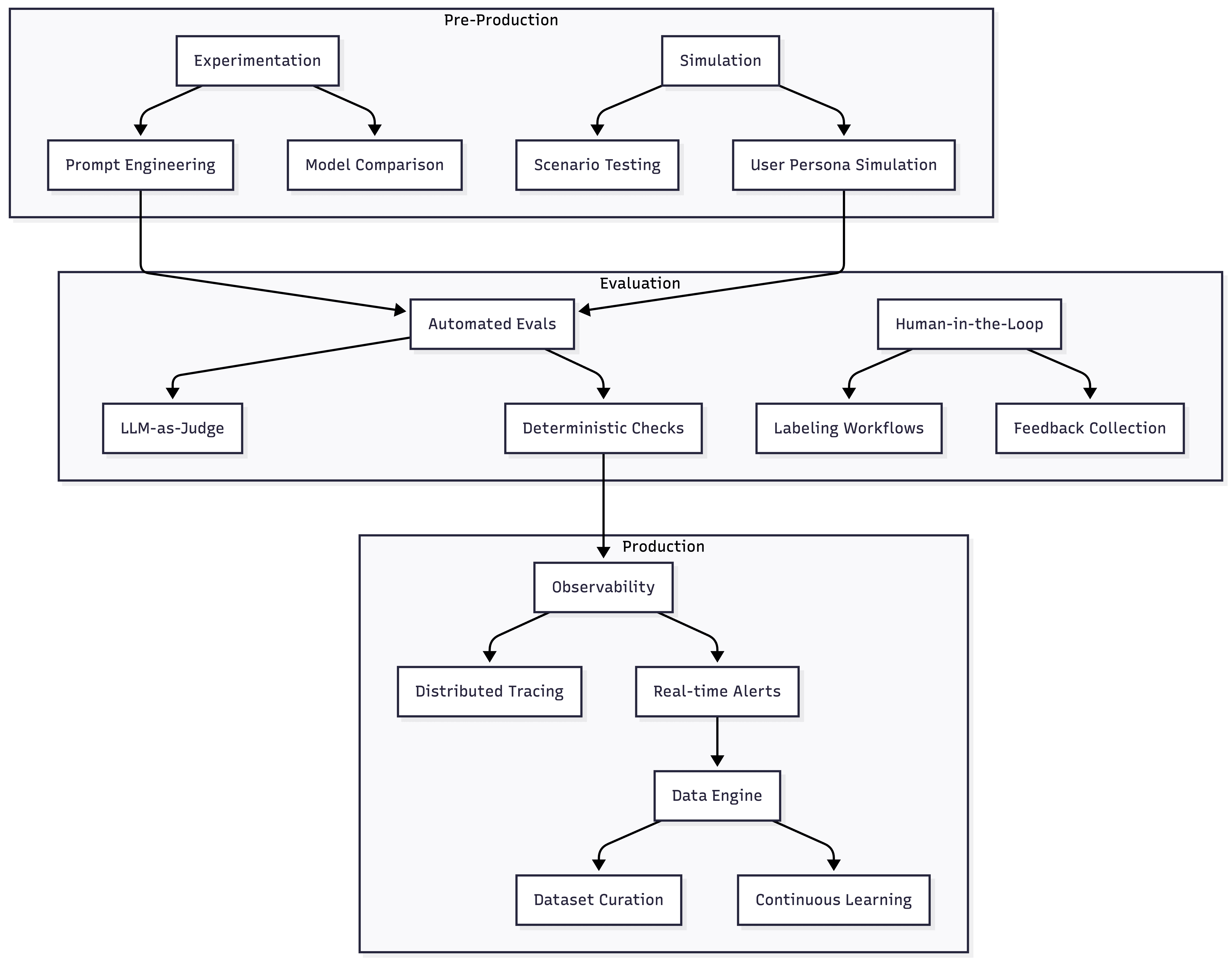
The most comprehensive platforms cover all three stages: pre-production experimentation and simulation, evaluation workflows combining automated and human review, and production observability with data feedback loops.
1. Maxim AI: Full-Stack AI Quality Platform
Overview: Maxim AI is an end-to-end AI simulation, evaluation, and observability platform designed for teams shipping AI agents reliably. Unlike point solutions that address only tracing or evaluation, Maxim covers the entire AI lifecycle from experimentation through production monitoring.
Key Capabilities
Agent Simulation and Evaluation
- Simulate customer interactions across real-world scenarios and user personas
- Evaluate agents at conversational and trajectory levels
- Re-run simulations from any step to reproduce issues and identify root causes
- Access pre-built evaluators or create custom evaluators (deterministic, statistical, LLM-as-a-judge)
Learn more: Agent Simulation and Evaluation
Production Observability
- Real-time distributed tracing for multi-agent systems
- Automated evaluations based on custom rules
- Custom dashboards for deep insights across agent behavior
- Instant alerts for production quality issues
Learn more: Agent Observability
Experimentation (Playground++)
- Advanced prompt engineering with version control
- Deploy prompts with different deployment variables without code changes
- Compare output quality, cost, and latency across prompt/model combinations
Learn more: Experimentation Platform
Data Engine
- Import and manage multimodal datasets
- Curate datasets from production data continuously
- Human-in-the-loop labeling and feedback workflows
Why Teams Choose Maxim Over Arize
| Dimension | Maxim AI | Arize AI |
|---|---|---|
| Pre-production testing | Comprehensive simulation | Limited |
| Cross-functional UX | Product + Engineering | Engineering-centric |
| Evaluation flexibility | Session/trace/span level | Primarily trace level |
| Agent workflow support | Native multi-agent | Added capability |
| Human-in-the-loop | Deeply integrated | Basic annotations |
Highlight: Maxim's flexi evals allow product teams to configure evaluations without code, breaking down the engineering dependency that slows AI iteration cycles.
Best for: Teams building production AI agents who need end-to-end quality management and cross-functional collaboration between engineering and product.
2. LangSmith: LangChain Ecosystem Observability
Overview: LangSmith is the observability and evaluation platform built by the LangChain team. It provides deep integration with LangChain and LangGraph, making it a natural choice for teams already invested in that ecosystem.
Key Capabilities
- Native LangChain/LangGraph tracing: Automatic instrumentation with one environment variable
- Prompt versioning: Track and compare prompt variations with full history
- Dataset-driven testing: Run predefined test suites across application versions
- LLM-as-judge evaluation: Automated scoring for correctness, relevance, and coherence
Considerations
- Ecosystem lock-in: LangSmith works best within the LangChain ecosystem. Teams using other frameworks or custom implementations may find integration more challenging.
- Self-hosting limitations: Self-hosting is only available on Enterprise plans, which may not suit teams with strict data residency requirements on smaller budgets.
- Product team access: The platform is primarily designed for developers, with limited no-code capabilities for non-technical stakeholders.
3. Langfuse: Open-Source LLM Engineering
Overview: Langfuse is an open-source LLM observability platform offering tracing, prompt management, and evaluation capabilities. Its MIT license and self-hosting flexibility make it attractive for teams prioritizing data sovereignty.
Key Capabilities
- Comprehensive tracing: Track LLM calls, retrieval, embeddings, and agent actions
- Prompt management: Centralized versioning with strong caching
- Cost tracking: Automatic token usage and cost calculation across providers
- Multiple evaluation approaches: LLM-as-judge, user feedback, manual labeling, and custom pipelines
Considerations
- Self-hosting complexity: While Langfuse can be self-hosted easily with Docker, production deployments at scale require more infrastructure expertise.
- Evaluation maturity: Evaluation capabilities, while improving, are less comprehensive than purpose-built evaluation platforms.
- Limited simulation: Langfuse focuses on observability rather than pre-production agent simulation.
4. Comet Opik
Platform Overview
Comet Opik is an open-source platform for logging, evaluating, and monitoring LLM applications that extends Comet's established ML experiment tracking capabilities to agentic systems. Opik differentiates itself by unifying LLM observability with broader ML workflows, making it attractive for data science teams already using Comet for traditional machine learning.
Key Features
- Open-source and self-hostable: Full platform available for local deployment via Docker or Kubernetes
- 40+ framework integrations: Support for OpenAI Agents, Google ADK, AutoGen, CrewAI, LlamaIndex, and more
- Span-level metrics: Evaluate quality of individual steps within agent workflows, not just final outputs
- Agent optimizer: Automated agent improvement algorithms to maximize performance
- Online evaluation rules: Continuous quality monitoring with LLM-as-a-judge metrics in production
- Guardrails and anonymizers: Built-in safety mechanisms and PII protection for production systems
- Experiment tracking integration: Unified view of LLM experiments alongside traditional ML pipelines
- Dataset management: Training/validation splits and versioning for evaluation workflows
5. Weights & Biases Weave: ML Platform Extension
Overview: W&B Weave extends the Weights & Biases platform to cover LLM observability and evaluation. For teams already using W&B for traditional ML experiment tracking, Weave provides a unified environment for all AI work.
Key Capabilities
- Automatic tracing:
@weave.opdecorator captures inputs, outputs, costs, and latency without manual setup - Unified ML + LLM tracking: Single platform for traditional ML and generative AI experiments
- Interactive playground: Test and iterate on prompts with live model interaction
- Leaderboard visualization: Compare evaluations across models and configurations
Considerations
- ML-first design: Weave's strengths come from its ML heritage, which can feel less native for teams focused exclusively on LLM applications.
- Learning curve: Teams new to the W&B ecosystem may face a steeper onboarding compared to LLM-native tools.
- Agent workflow gaps: While Weave handles single LLM calls well, complex multi-agent orchestration may require additional tooling.
Feature Comparison Matrix
| Feature | Maxim AI | LangSmith | Langfuse | Comet Opik | W&B Weave |
|---|---|---|---|---|---|
| Distributed tracing | ✅ | ✅ | ✅ | ✅ | ✅ |
| Agent simulation | ✅ | ❌ | ❌ | Partial | ❌ |
| Custom evaluators | ✅ | ✅ | ✅ | ✅ | ✅ |
| No-code evaluation | ✅ | Limited | Limited | Limited | Limited |
| Human-in-the-loop | ✅ | ✅ | ✅ | ✅ | Partial |
| Prompt management | ✅ | ✅ | ✅ | ✅ | ✅ |
| Self-hosting | ✅ | Enterprise | ✅ | Enterprise | ❌ |
| Multi-agent support | ✅ | ✅ | ✅ | ✅ | Partial |
| Cost tracking | ✅ | ✅ | ✅ | ✅ | ✅ |
Decision Framework
The following diagram helps visualize which platform fits different team profiles and requirements:
Choose Maxim AI if:
- You need end-to-end coverage from simulation through production
- Product and engineering teams need to collaborate on AI quality
- You're building complex multi-agent systems
- Human-in-the-loop evaluation is critical to your workflow
Choose LangSmith if:
- Your stack is built on LangChain/LangGraph
- Deep framework integration matters more than flexibility
- You're primarily focused on debugging and tracing
Choose Langfuse if:
- Open-source and self-hosting are non-negotiable requirements
- You have engineering resources to manage infrastructure
- You need a cost-effective starting point
Choose Comet if:
- LLM observability with broader ML workflows
- for data science teams already using Comet for traditional machine learning
Choose W&B Weave if:
- You're already using Weights & Biases for ML
- Unified tracking across ML and LLM matters
- Your LLM use cases are relatively straightforward
Making the Right Choice
The AI observability market has matured significantly, and no single platform is universally superior. Your choice should align with your team's composition, technical requirements, and workflow preferences.
However, if you're building production AI agents and need a platform that serves both engineering rigor and product team accessibility, Maxim AI provides the most comprehensive approach. Its full-stack coverage, from experimentation through simulation to production observability, eliminates the need to stitch together multiple point solutions.
Further Reading
Internal Resources
- Agent Tracing for Debugging Multi-Agent AI Systems
- LLM Observability Guide
- Maxim AI vs. Arize Comparison
- Maxim AI vs. Langfuse Comparison
- Maxim AI Documentation
External Resources
- OpenTelemetry Semantic Conventions for GenAI
- NIST AI Risk Management Framework
- MLOps Community Best Practices
Get Started with Maxim AI
Ready to see how Maxim AI can help your team ship reliable AI agents faster?
Schedule a Demo to see the platform in action, or Sign Up Free to start exploring immediately.
Our team provides hands-on partnership throughout your journey, from initial setup to enterprise-scale deployments with industry-leading SLAs.


