

Top 5 LLM Gateways for Scaling AI Applications in 2025

TLDR
Key Takeaways:
- LLM gateways solve critical production challenges, including provider lock-in, reliability issues, cost management, and operational complexity
- Bifrost by Maxim AI leads the market with 50x faster performance than LiteLLM, adding less than 11µs overhead at 5,000 RPS
- Enterprise features like automatic failover, semantic caching, and unified APIs enable production-ready AI deployments
- Open-source options provide flexibility while managed solutions accelerate deployment timelines
- The optimal gateway choice depends on performance requirements, scale, technical expertise, and integration needs
Table of Contents
- Why LLM Gateways Are Critical in 2025
- Key Selection Criteria
- Top 5 LLM Gateways for 2025
- Decision Framework
- Conclusion
Why LLM Gateways Are Critical in 2025
Direct API integration with LLM providers creates significant operational challenges as organizations scale their AI workloads. According to industry analysis, teams encounter four critical problems when managing multiple LLM providers in production environments.
Provider Lock-in Risks
- Application codebases become tightly coupled to specific provider API formats
- Provider switches require complete code rewrites across systems
- Limited flexibility to optimize for cost-performance tradeoffs across providers
Reliability and Availability Issues
- Single points of failure when providers experience regional outages
- No automatic fallback mechanisms during service disruptions
- Application downtime is directly correlated with provider availability
Cost Management Challenges
- Lack of real-time cost tracking and visibility across providers
- Difficulty implementing usage budgets and spending controls
- Unexpected monthly bills without granular monitoring capabilities
Operational Complexity
- Managing multiple API keys and authentication methods across providers
- Inconsistent request and response formats requiring custom handling logic
- Rate limiting and quota management are distributed across disconnected systems
An LLM gateway functions as a unified service layer that brokers requests between applications and multiple model providers. The gateway exposes a consistent API while handling orchestration, authentication, governance, caching, and observability across providers.
Key Selection Criteria
Organizations evaluating LLM gateways for production deployments should assess vendors across five critical dimensions.
Performance Metrics
- Request latency overhead added by the gateway layer
- Maximum throughput capacity measured in requests per second
- Memory and CPU efficiency under sustained load
- Horizontal scalability capabilities for high-traffic deployments
Provider Coverage
- Number of supported LLM providers and models
- API compatibility and standardization across providers
- Support for custom model deployments and self-hosted options
- Multi-provider failover and load balancing capabilities
Enterprise Features
- Access control mechanisms and authentication systems
- Usage tracking and cost management controls
- Semantic caching for cost reduction and latency improvement
- Compliance frameworks and security controls
Developer Experience
- Setup complexity and deployment time requirements
- SDK integration patterns and code migration effort
- Documentation quality and community support
- Configuration flexibility through UI, API, or files
Observability Capabilities
- Request tracing and comprehensive logging
- Performance monitoring dashboards
- Error tracking and alerting systems
- Analytics and reporting frameworks
Top 5 LLM Gateways for 2025
1. Bifrost by Maxim AI
Platform Overview
Bifrost is a high-performance AI gateway that unifies access to 1000+ models across 15+ providers through a single OpenAI-compatible API. Built in Go for maximum performance, Bifrost adds less than 11µs overhead at 5,000 requests per second, making it 50x faster than alternative solutions like LiteLLM.
The gateway achieves production-ready deployment in under 30 seconds with zero configuration requirements. Bifrost's architecture supports OpenAI, Anthropic, AWS Bedrock, Google Vertex AI, Azure OpenAI, Cohere, Mistral AI, Groq, Ollama, and additional providers through a unified interface.
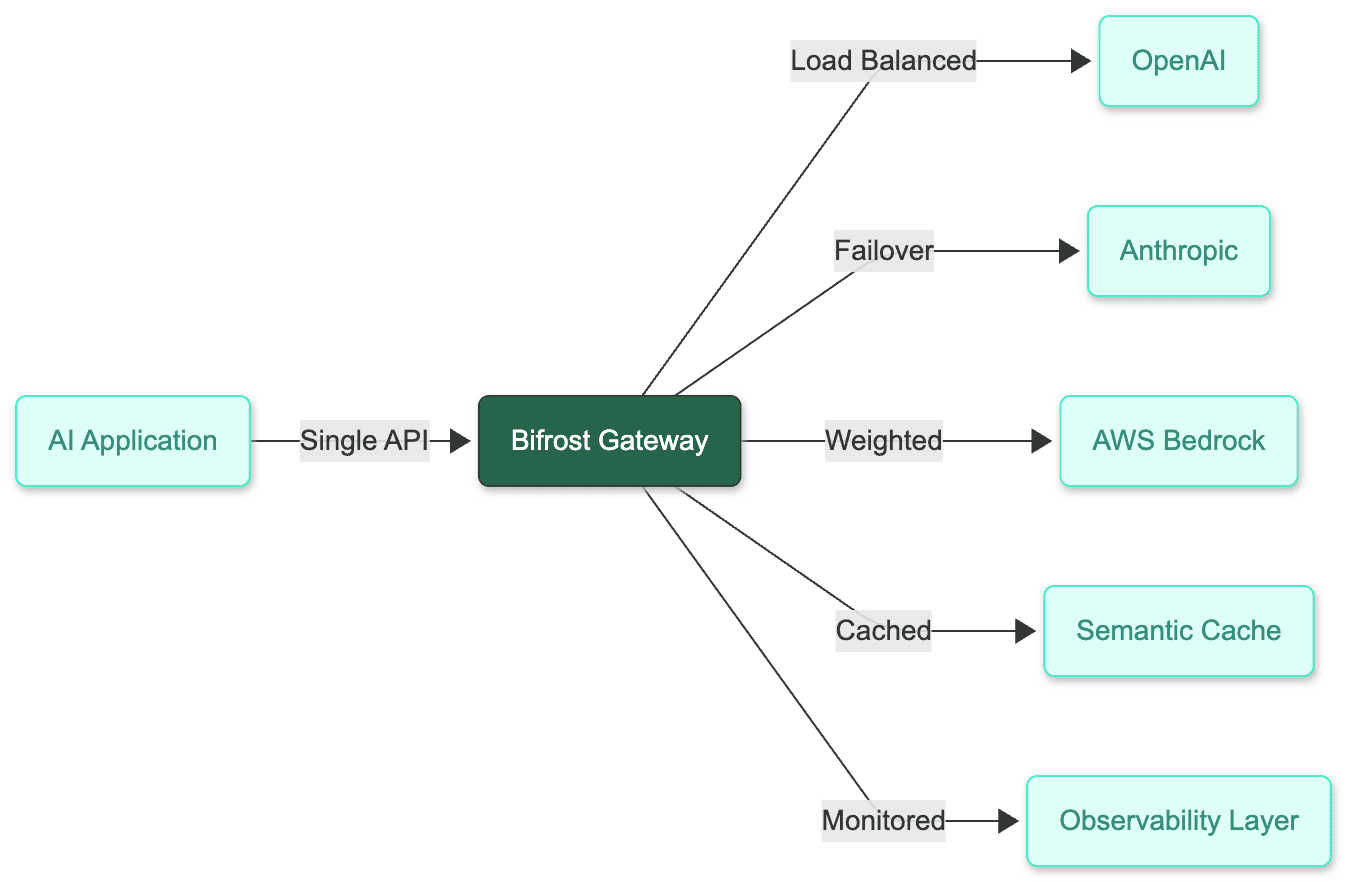
Key Features
Core Infrastructure
- Unified Interface: Single OpenAI-compatible API standardizes access across all providers
- Eliminates provider-specific SDK management overhead
- Enables one-line base URL changes for seamless migration
- Maintains consistent request and response formats
- Multi-Provider Support: Native integration with 15+ providers and 1000+ models
- OpenAI, Anthropic, AWS Bedrock, Google Vertex AI, Azure OpenAI
- Cerebras, Cohere, Mistral AI, Groq, Perplexity
- Ollama for self-hosted model deployments
- Custom model deployment capabilities
- Automatic Fallbacks: Zero-downtime provider switching during outages
- Health-aware routing with circuit breaker patterns
- Automatic provider recovery testing and validation
- Request replay mechanisms on failure scenarios
- Adaptive Load Balancing: Intelligent request distribution optimization
- Weighted key selection across multiple providers
- Performance-based routing decisions
- Regional load balancing for global deployments
Advanced Capabilities
- Model Context Protocol (MCP): External tool integration framework
- Filesystem access for AI agents
- Web search integration capabilities
- Database connectivity options
- Custom tool execution environments
- Semantic Caching: Intelligent response caching system
- Redis-based caching infrastructure with configurable TTL
- Cost reduction up to 95% through cache hits
- Cross-provider compatibility for cached responses
- Semantic similarity matching algorithms
- Multimodal Support: Comprehensive input handling
- Text, image, and audio processing capabilities
- Streaming response support
- Unified interface across all modalities
- Custom Plugins: Extensible middleware architecture
- Plugin-first design without callback complexity
- Simplified custom plugin creation
- Integration with analytics and monitoring systems
Enterprise Security and Governance
- Governance Controls: Fine-grained access management
- Multi-level rate limiting across users, teams, providers, and global limits
- Virtual key generation for team isolation
- Hierarchical budget management systems
- Usage tracking and spending limit enforcement
- SSO Integration: Enterprise authentication
- Google and GitHub SSO support
- Role-based access control mechanisms
- Team management capabilities
- Vault Support: Secure credential management
- HashiCorp Vault integration
- Encrypted API key storage
- Automatic key rotation policies
- Observability: Production monitoring infrastructure
- Native Prometheus metrics export
- Distributed tracing capabilities
- Comprehensive request logging
- Real-time monitoring dashboards
Developer Experience
- Zero-Config Startup: Instant deployment capability
- Installation and execution in under 30 seconds:
npx -y @maximhq/bifrost - No configuration files required for initial deployment
- Dynamic provider setup through Web UI
- Installation and execution in under 30 seconds:
- Drop-in Replacement: Seamless migration path
- OpenAI SDK compatibility with base URL change only
- Anthropic SDK compatibility
- Google GenAI SDK compatibility
- LangChain and LlamaIndex framework support
- Configuration Flexibility: Multiple setup methodologies
- Web UI for visual configuration management
- API-driven configuration for automation workflows
- File-based configuration for GitOps deployments
Performance Benchmarks
Bifrost demonstrates exceptional performance in production environments. In sustained 5,000 RPS benchmarks on a t3.xlarge instance, the gateway adds only 11µs of overhead per request.
| Metric | t3.medium | t3.xlarge | Improvement |
|---|---|---|---|
| Added latency (overhead) | 59µs | 11µs | 81% reduction |
| Success rate at 5K RPS | 100% | 100% | Zero failures |
| Average queue wait time | 47µs | 1.67µs | 96% reduction |
| Average total latency | 2.12s | 1.61s | 24% reduction |
Performance highlights include:
- 100% request success rate at 5,000 RPS sustained load
- Less than 15µs additional latency per request
- Sub-microsecond average queue wait times
- Approximately 10 nanoseconds for weighted key selection
Best For
Bifrost is optimal for organizations requiring:
- High-scale production applications with strict latency requirements
- Enterprise deployments demanding comprehensive governance and security controls
- Multi-provider architectures requiring automatic failover and intelligent load balancing
- Development teams seeking rapid deployment with minimal configuration overhead
- Organizations integrating with Maxim's end-to-end AI evaluation and observability platform
Integration with Maxim Platform
Bifrost functions as the gateway layer within Maxim's comprehensive AI lifecycle platform:
- Experimentation: Rapid prompt engineering and testing workflows
- Simulation: AI-powered agent testing across diverse scenarios
- Evaluation: Unified machine and human evaluation frameworks
- Observability: Real-time production monitoring and quality assurance
2. Cloudflare
Platform Overview
Cloudflare AI Gateway provides a unified interface to connect with major AI providers including Anthropic, Google, Groq, OpenAI, and xAI, offering access to over 350 models across 6 different providers
Key Features
- Multi-provider support: Works with Workers AI, OpenAI, Azure OpenAI, HuggingFace, Replicate, Anthropic, and more
- Performance optimization: Advanced caching mechanisms to reduce redundant model calls and lower operational costs
- Rate limiting and controls: Manage application scaling by limiting the number of requests
- Request retries and model fallback: Automatic failover to maintain reliability
- Real-time analytics: View metrics including number of requests, tokens, and costs to run your application with insights on requests and errors
- Comprehensive logging: Stores up to 100 million logs in total (10 million logs per gateway, across 10 gateways) with logs available within 15 seconds
- Dynamic routing: Intelligent routing between different models and providers
3. LiteLLM
Platform Overview
LiteLLM is an open-source gateway supporting 100+ models through a unified API with broad framework compatibility, including LangChain and LlamaIndex. The gateway provides basic routing and provider abstraction for rapid integration.
Key Features
- Extensive Model Support: Access to 100+ models through standardized interface
- Framework Integration: Native LangChain and LlamaIndex compatibility
- Quick Setup: Rapid prototyping capabilities with minimal configuration
- Pass-through Billing: Centralized cost management across providers
- Basic Routing: Simple failover and load balancing mechanisms
Best For
- Engineering teams building custom LLM infrastructure
- Rapid prototyping and experimentation workflows
- Organizations with moderate scale requirements
4. Vercel
Platform Overview
Vercel AI Gateway, now generally available, provides a single endpoint to access hundreds of AI models across providers with production-grade reliability. The platform emphasizes developer experience, with deep integration into Vercel's hosting ecosystem and framework support.
Key Features
- Multi-provider support: Access to hundreds of models from OpenAI, xAI, Anthropic, Google, and more through a unified API
- Low-latency routing: Consistent request routing with latency under 20 milliseconds designed to keep inference times stable regardless of provider
- Automatic failover: If a model provider experiences downtime, the gateway automatically redirects requests to an available alternative
- OpenAI API compatibility: Compatible with OpenAI API format, allowing easy migration of existing applications
- Observability: Per-model usage, latency, and error metrics with detailed analytics
5. Kong AI Gateway
Platform Overview
Kong AI Gateway extends Kong's proven API gateway platform to support LLM routing, providing features including observability, semantic security and caching, and routing
Key Features
- Multi-provider routing with support for OpenAI, Anthropic, Cohere, Azure OpenAI, and custom endpoints through Kong's plugin architecture.
- Request/response transformation: Normalize formats across different providers
- Rate limiting and quota management: Token analytics and cost tracking
- Enterprise security: Authentication, authorization, mTLS, API key rotation
- MCP support: Centralized MCP server management
- Extensive plugin marketplace
Decision Framework
Selecting a gateway depends on reliability needs, governance requirements, integration depth, and team workflows.
- Reliability and failover:
- Evaluate automatic fallbacks, circuit breaking, and multi-region redundancy. For mission-critical apps, prioritize proven failover like Bifrost’s fallbacks.
- Observability and tracing:
- Ensure distributed tracing, span-level visibility, and metrics export. Bifrost’s observability integrates Prometheus and structured logs.
- Cost and latency:
- Seek semantic caching to cut costs and tail latency; ensure budgets and rate limits per team/customer.
- Security and governance:
- Confirm SSO, Vault support, scoped keys, and RBAC.
- Developer experience:
- Prefer OpenAI-compatible drop-in APIs and flexible configuration. •
- Lifecycle integration:
- Align with prompt versioning, evals, agent simulation, and production ai monitoring. Maxim’s full-stack approach supports pre-release to post-release needs.
Conclusion
LLM gateways have evolved from optional infrastructure components to mission-critical systems for production AI applications in 2025. According to recent industry analysis, gateways serve as the convergence point for multi-provider resilience, security controls, performance optimizations, and observability capabilities.
Critical Considerations:
- Performance differences at scale impact both production costs and user experience significantly, with overhead variations of 50x between solutions
- Enterprise features including semantic caching, governance controls, and automatic failover have transitioned from optional to required capabilities
- Open-source options provide flexibility and transparency for teams building custom infrastructure solutions
- Integration with comprehensive AI evaluation and observability platforms accelerates development cycles and improves deployment reliability
Bifrost by Maxim AI establishes the performance benchmark for LLM gateways while delivering enterprise-grade features in a zero-configuration deployment package. The gateway's integration with Maxim's end-to-end platform provides teams with the shortest path to scalable, reliable agentic applications across the complete AI lifecycle.
Ready to eliminate gateway bottlenecks and build production-ready AI applications? Request a demo to see how Bifrost and Maxim's comprehensive platform can accelerate your AI development workflow, or sign up today to deploy your gateway in under 30 seconds.


