Top 5 prompt evaluation tools in 2025

Table of Contents
- TL;DR
- Understanding Prompt Evaluation
- Why Prompt Evaluation Matters in 2025
- Key Evaluation Criteria for Prompt Testing Platforms
- Top 5 Prompt Evaluation Tools
- Comparative Analysis
- Prompt Evaluation Workflow
- Implementation Best Practices
- Conclusion
TL;DR
Effective prompt evaluation has become essential for teams building production-grade AI applications. This guide analyzes five leading prompt evaluation platforms for 2025:
- Maxim AI: End-to-end platform with advanced experimentation, simulation testing, and cross-functional collaboration capabilities
- Langfuse: Open-source observability platform with flexible evaluation framework and self-hosting support
- Arize AI: Production-focused monitoring with drift detection and enterprise-scale observability
- Galileo: Experimentation-centric platform with rapid prototyping capabilities
- LangSmith: LangChain-native debugging with comprehensive tracing and dataset management
Organizations should select platforms based on their specific requirements for lifecycle coverage, collaboration workflows, deployment models, and integration needs.
Understanding Prompt Evaluation
Prompt evaluation represents the systematic process of testing, measuring, and optimizing the instructions provided to large language models to ensure consistent, high-quality outputs. Unlike ad hoc prompt testing, structured prompt evaluation treats prompts as critical application components requiring rigorous quality assurance.
The evaluation process encompasses multiple dimensions:
- Functional Quality: Testing whether prompts produce accurate, relevant, and task-appropriate outputs across diverse scenarios
- Performance Metrics: Measuring response latency, token consumption, and computational efficiency
- Safety and Compliance: Ensuring outputs remain free from bias, toxicity, harmful content, and regulatory violations
- User Experience: Assessing subjective qualities including tone, helpfulness, and conversational flow
- Regression Detection: Identifying when prompt modifications introduce unexpected behavior changes
Key Evaluation Criteria for Prompt Testing Platforms
Organizations evaluating prompt testing platforms should assess capabilities across several critical dimensions:
Multi-Model Support
- Coverage across major LLM providers (OpenAI, Anthropic, Google, AWS Bedrock, Azure)
- Support for open-source models and custom deployments
- Ability to compare outputs across different model families
Version Control and Collaboration
- Comprehensive prompt versioning with change tracking
- Collaborative editing interfaces for cross-functional teams
- Role-based access controls and approval workflows
Evaluation Frameworks
- Automated metrics (accuracy, relevance, coherence, toxicity)
- Human-in-the-loop evaluation capabilities
- Custom evaluator support for domain-specific requirements
Production Integration
- CI/CD pipeline integration for automated testing
- Production monitoring and alerting
- Deployment controls and rollback capabilities
Enterprise Requirements
- SOC 2, ISO 27001, HIPAA, GDPR compliance
- Self-hosting and in-VPC deployment options
- SSO integration and advanced RBAC
Top 5 Prompt Evaluation Tools
1. Maxim AI
Platform Overview
Maxim AI provides an end-to-end platform for AI experimentation, simulation, evaluation, and observability, enabling teams to ship AI agents reliably and more than 5x faster. The platform addresses the complete AI lifecycle from prompt engineering through production monitoring with unified workflows designed for cross-functional collaboration.
Key Features
Advanced Experimentation Platform
Maxim's Playground++ provides enterprise-grade prompt engineering capabilities:
- Direct UI-based prompt organization and versioning: Teams can structure prompts using folders, tags, and metadata without navigating code repositories
- Deployment variables and experimentation strategies: A/B test prompt variants without code changes through deployment rules
- Seamless context integration: Connect databases, RAG pipelines, and tool definitions directly within prompt workflows
- Comprehensive comparison dashboards: Evaluate output quality, cost, and latency across prompt-model-parameter combinations
- Multimodal support: Test prompts with text, images, audio, and structured outputs
Agent Simulation and Evaluation
Simulation capabilities distinguish Maxim from traditional prompt management tools:
- Scenario-based testing: Simulate customer interactions across real-world scenarios and user personas
- Conversational trajectory analysis: Monitor agent responses at every step and assess task completion success
- Root cause debugging: Re-run simulations from any step to reproduce issues and identify failure points
- Scale testing: Evaluate agent performance across hundreds of scenarios before production deployment
- Multi-turn evaluation: Assess prompt effectiveness in extended conversational contexts
Unified Evaluation Framework
Maxim's evaluation infrastructure combines multiple assessment approaches:
- Pre-built evaluator library: Access off-the-shelf evaluators for common quality dimensions through the evaluator store
- Custom evaluator support: Create domain-specific evaluators using LLM-as-a-judge, statistical, or programmatic approaches
- Multi-level granularity: Configure evaluations at session, trace, or span level for fine-grained assessment
- Human-in-the-loop workflows: Define and conduct human evaluations for last-mile quality checks
- Batch evaluation capabilities: Run comprehensive test suites across multiple prompt versions simultaneously
Production Observability
Observability features enable continuous prompt quality monitoring:
- Distributed tracing: Track, debug, and resolve live quality issues with real-time alerts
- Automated production evaluations: Measure in-production quality using custom rules and periodic checks
- Dataset curation: Continuously evolve test datasets from production data and user feedback
- Custom dashboards: Create insights across agent behavior with configurable analytics
- Multi-repository support: Manage production data for multiple applications independently
Cross-Functional Collaboration
Maxim's design philosophy centers on seamless collaboration between engineering and product teams:
- No-code UI workflows: Product managers can define, run, and analyze evaluations without engineering dependencies
- Powerful SDK support: Python, TypeScript, Java, and Go SDKs provide programmatic control for technical workflows
- Shared workspace model: Engineering and product teams work in unified environments with consistent data access
- Intuitive visualization: Clear dashboards and reports enable non-technical stakeholders to drive optimization
Best For
Maxim AI is ideal for:
- Organizations requiring end-to-end lifecycle management spanning experimentation, simulation, evaluation, and observability
- Teams building complex, multi-step agentic workflows requiring comprehensive testing before deployment
- Cross-functional environments where product managers need active participation in prompt optimization
- Enterprises prioritizing systematic quality assurance with human-in-the-loop validation
- Applications in regulated industries requiring audit trails and compliance documentation
- Teams seeking unified platforms to reduce integration complexity across fragmented tooling
2. Langfuse
Platform Overview
Langfuse is an open-source platform for LLM observability and evaluation, providing logging, tracing, and evaluation capabilities with self-hosting support.
Key Features
- Open-source architecture: Self-host with complete deployment control and data sovereignty
- Comprehensive tracing: Visualize LLM call sequences and component interactions for debugging
- Model-based evaluations: Automated assessments using LLM-as-a-judge for quality dimensions
- Custom evaluators: Define evaluation prompts with variable placeholders and scoring logic
- Prompt versioning: Track modifications with rollback capabilities and collaborative editing
- Dataset management: Curate test datasets from production data for reproducible evaluation
Best For
- Teams with DevOps capabilities valuing open-source principles and infrastructure control
- Organizations requiring data sovereignty for privacy-sensitive applications
- Companies in regulated industries requiring self-hosted solutions
3. Arize AI
Platform Overview
Arize AI specializes in model observability and performance monitoring for ML and LLM systems in production, focusing on drift detection and real-time alerting at enterprise scale.
Key Features
- Production monitoring dashboards: Real-time visibility into model behavior and output quality metrics
- Drift detection: Identify when prompt effectiveness degrades due to model updates or data changes
- Anomaly alerting: Automatic notifications through Slack, PagerDuty, OpsGenie for quality issues
- Multi-level tracing: Session, trace, and span-level visibility for LLM workflows
- Enterprise compliance: SOC 2, GDPR, HIPAA compliance with advanced RBAC and audit trails
Best For
- Organizations prioritizing production monitoring over pre-deployment evaluation
- Enterprises with mature ML infrastructure extending monitoring to LLM applications
- Teams requiring robust drift detection and compliance features
4. Galileo
Platform Overview
Galileo provides an experimentation-centric platform for rapid prototyping and testing of LLM prompts and workflows, emphasizing speed for early-stage development.
Key Features
- Prompt playground: Interactive environment for rapid prompt prototyping and testing
- Quick model comparison: Evaluate outputs across different LLM providers with minimal setup
- Performance insights: Track quality metrics, cost analysis, and latency profiling
- Human review integration: Annotation interfaces and feedback aggregation for refinement
Best For
- Teams prioritizing speed in early-stage LLM application development
- Organizations focused on rapid experimentation without complex evaluation requirements
- Small to medium teams needing straightforward prototyping capabilities
5. LangSmith
Platform Overview
LangSmith specializes in tracing and debugging LLM applications built with LangChain, providing first-class support for LangChain's composable primitives.
Key Features
- LangChain-native integration: Deep integration with LangChain ecosystem and chain-level introspection
- Comprehensive tracing: Step-by-step visualization and input/output tracking at each chain stage
- Dataset-driven testing: Test suite management with regression testing and version comparison
- Collaboration features: Shared runs, version tracking, and team access controls
Best For
- Teams deeply invested in the LangChain ecosystem
- Applications with chain-centric architectures requiring component-level debugging
- Python-centric development environments building with LangChain primitives
Comparative Analysis
Feature Comparison Matrix
| Feature | Maxim AI | Langfuse | Arize AI | Galileo | LangSmith |
|---|---|---|---|---|---|
| End-to-End Platform | ✓ | ✗ | ✗ | ✗ | ✗ |
| Prompt Versioning | ✓ | ✓ | Limited | ✓ | ✓ |
| Agent Simulation | ✓ | ✗ | ✗ | ✗ | ✗ |
| A/B Testing | ✓ | ✓ | Limited | ✓ | ✓ |
| Custom Evaluators | ✓ | ✓ | Limited | Limited | ✓ |
| Human-in-the-Loop | ✓ | ✓ | ✗ | ✓ | Limited |
| Production Monitoring | ✓ | ✓ | ✓ | Limited | ✓ |
| Open Source | ✗ | ✓ | ✗ | ✗ | ✗ |
| Self-Hosting | ✓ | ✓ | Limited | ✗ | ✗ |
| Multi-Model Support | ✓ | ✓ | ✓ | ✓ | ✓ |
| Cross-Functional UI | ✓ | Limited | Limited | ✓ | Limited |
| Dataset Management | ✓ | ✓ | Limited | ✗ | ✓ |
Deployment Coverage Comparison
Platform Coverage Analysis:
- Maxim AI: Comprehensive coverage across all stages with unified workflows
- Langfuse: Strong in development and production monitoring; limited simulation capabilities
- Arize AI: Focused on production monitoring and continuous evaluation
- Galileo: Emphasizes rapid experimentation; limited production features
- LangSmith: Strong in development and testing; production monitoring available
Collaboration Model Comparison
| Platform | Engineering Focus | Product Team Access | Cross-Functional Workflows |
|---|---|---|---|
| Maxim AI | High (SDKs + UI) | High (No-code UI) | Optimized |
| Langfuse | High | Medium | Developer-centric |
| Arize AI | High | Low | Engineering-focused |
| Galileo | Medium | Medium | Balanced |
| LangSmith | High | Low | Developer-centric |
Integration and Deployment Options
| Platform | Cloud Hosted | Self-Hosted | In-VPC Deployment | Enterprise SSO |
|---|---|---|---|---|
| Maxim AI | ✓ | ✓ | ✓ | ✓ |
| Langfuse | ✓ | ✓ | ✓ | Limited |
| Arize AI | ✓ | Limited | ✓ | ✓ |
| Galileo | ✓ | ✗ | Enterprise only | ✓ |
| LangSmith | ✓ | ✗ | Enterprise only | ✓ |
Prompt Evaluation Workflow
Effective prompt evaluation requires systematic workflows combining automated testing, human validation, and continuous monitoring. The following framework represents best practices for production-grade prompt management:
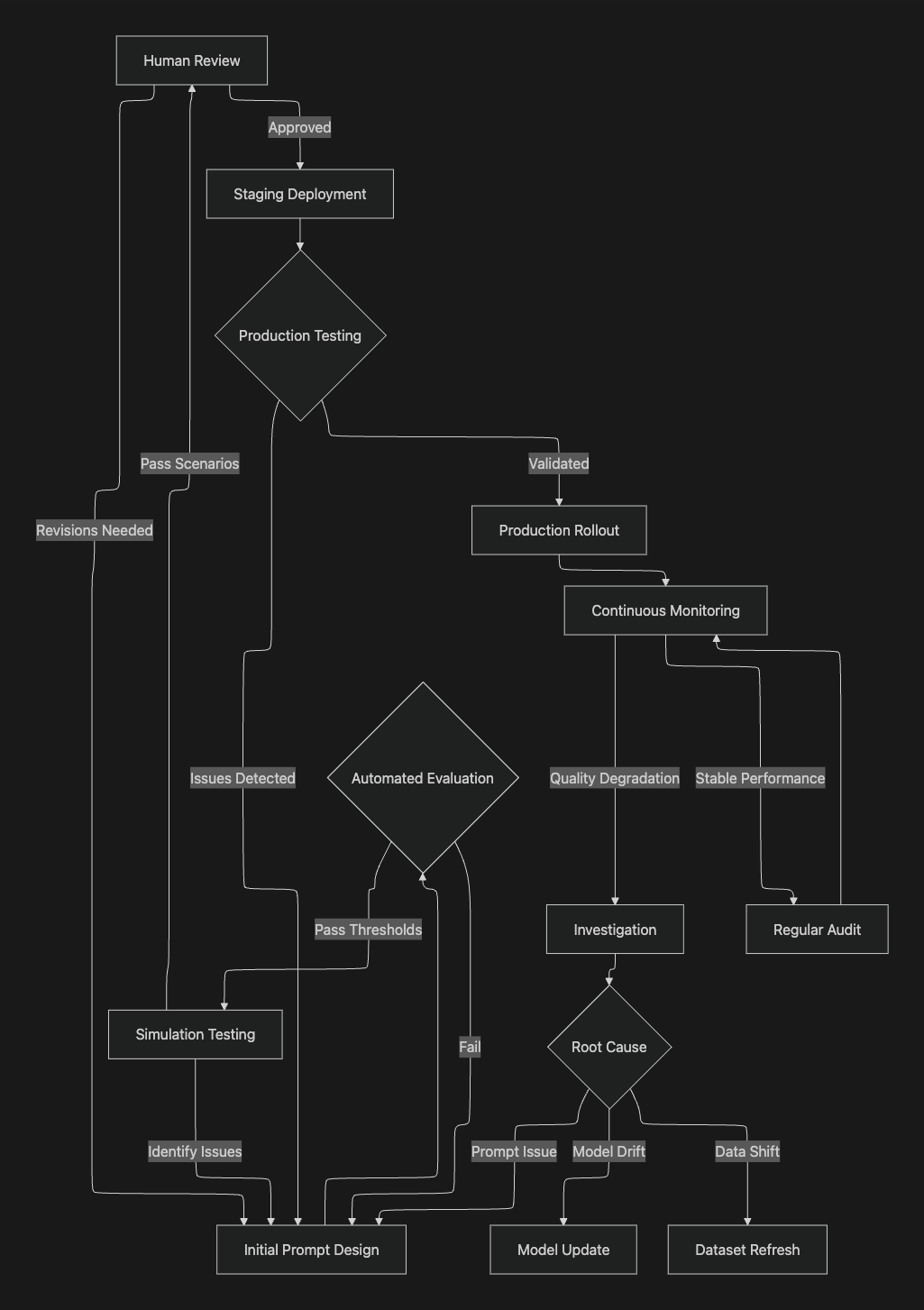
Workflow Stage Details
Initial Design Phase
- Define prompt objectives and success criteria
- Create baseline prompt versions with clear documentation
- Establish evaluation metrics aligned with business requirements
Automated Evaluation
- Run systematic tests across representative datasets
- Measure quality dimensions (accuracy, relevance, coherence, safety)
- Compare outputs across model and parameter variations
- Generate quantitative performance reports
Simulation Testing
- Test prompts in realistic conversational scenarios
- Evaluate multi-turn interaction quality
- Assess tool usage and decision-making patterns
- Identify edge cases and failure modes
Human Review
- Subject matter expert assessment of nuanced outputs
- Validation against domain-specific requirements
- Feedback collection for continuous improvement
- Final quality gate before production deployment
Production Deployment
- Gradual rollout with monitoring
- A/B testing against baseline prompts
- Automated quality checks on production traffic
- Rollback procedures for quality issues
Continuous Monitoring
- Real-time tracking of prompt performance metrics
- Drift detection and anomaly alerting
- User feedback integration
- Regular audit cycles for quality assurance
Conclusion
Prompt evaluation has evolved from an optional development practice to essential infrastructure for reliable AI applications. Organizations deploying production AI systems require systematic approaches to prompt testing and optimization that ensure consistent quality, manage costs, and maintain compliance requirements.
Ready to implement production-grade prompt evaluation for your AI applications? Explore Maxim AI to experience comprehensive experimentation, simulation, and evaluation capabilities designed for cross-functional teams building reliable AI systems. Our unified platform helps engineering and product teams collaborate seamlessly across the entire prompt lifecycle, reducing time-to-production while maintaining rigorous quality standards.
Schedule a demo to see how Maxim's end-to-end platform can accelerate your prompt evaluation workflows and help your team ship AI agents more than 5x faster.


