Top 5 Voice Agent Evaluation Tools in 2025

TL;DR: Voice agent evaluation requires assessing speech recognition accuracy, response latency, conversation flow quality, interruption handling, and goal completion across multi-turn dialogues. Effective evaluation demands visibility into ASR/TTS quality, tool calls, LLM reasoning, and real-time performance metrics. This guide compares the top five voice evaluation platforms: Maxim AI, Roark, Coval, Hamming AI, and Cekura.
Table of Contents
- Why Voice Agent Evaluation Matters
- Key Challenges in Voice Agent Evaluation
- The 5 Best Voice Agent Evaluation ToolsMaxim AIRoarkCovalHamming AICekura
- Platform Comparison
- Choosing the Right Tool
- Conclusion
Why Voice Agent Evaluation Matters
Voice AI agents operate in fundamentally different environments than text-based applications. According to research on conversational AI monitoring, voice interactions involve continuous audio streams, unpredictable speech patterns, and complex multi-service orchestration where single conversations touch STT (Speech-to-Text), LLM reasoning, and TTS (Text-to-Speech) providers simultaneously.
The real-time nature of voice conversations creates evaluation blind spots that standard application testing cannot address. A voice agent that performs well in controlled demos may fail catastrophically with regional accents, background noise, or when users interrupt mid-sentence. These failure modes only appear under production load with diverse user populations.
Without a comprehensive evaluation infrastructure, teams discover quality issues only after customer complaints. Minor transcription errors cascade into inappropriate responses. An additional 200ms latency creates interruption patterns that disrupt natural conversation flow. Integration failures with external APIs create awkward pauses that customers interpret as confusion or incompetence.
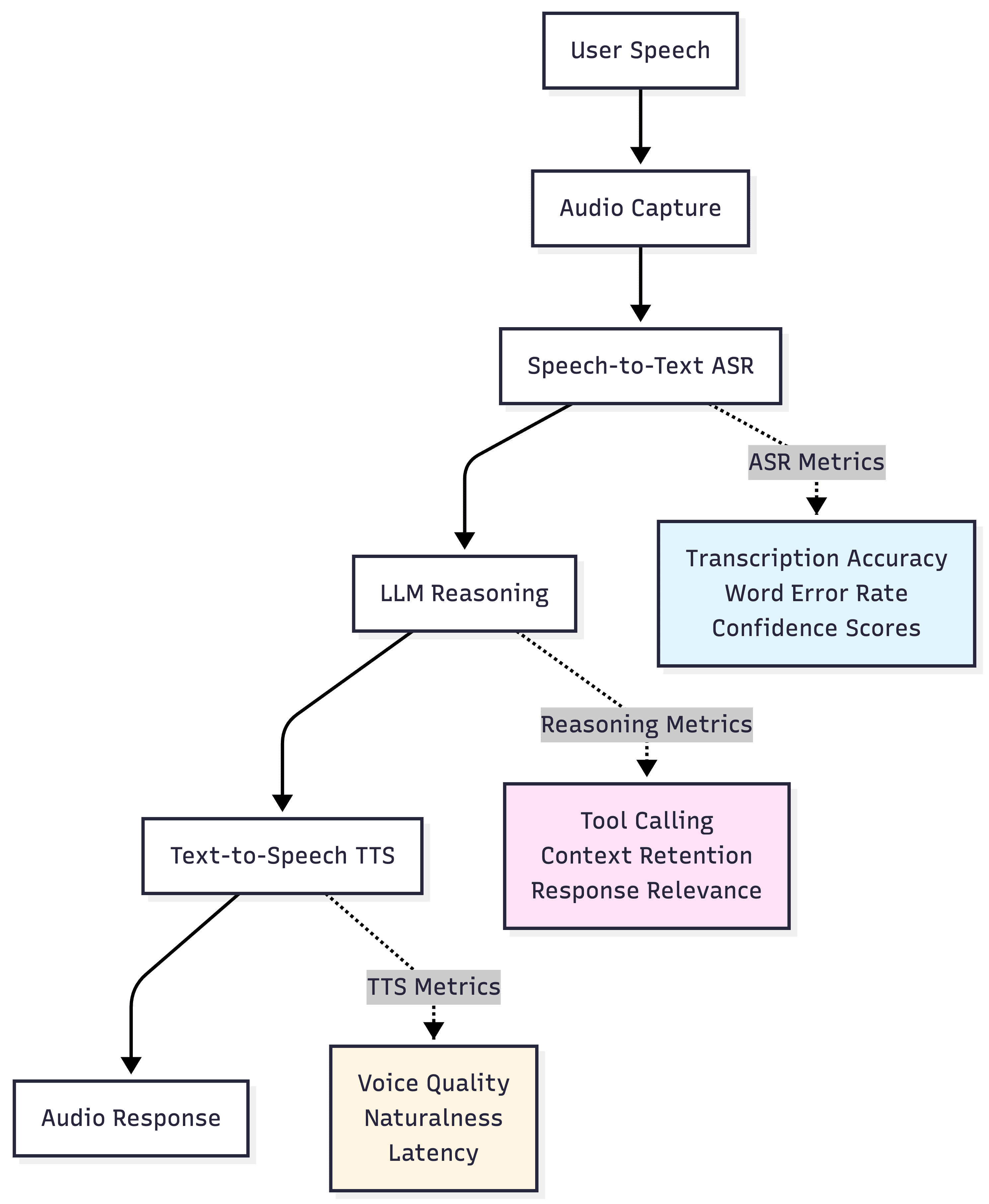
Key Challenges in Voice Agent Evaluation
Voice agent evaluation introduces unique complexities absent from text-based AI systems. Understanding these challenges informs platform selection and evaluation strategy.
Multi-Layer Performance Dependencies
Voice agents operate across interdependent layers where failures cascade unpredictably. The telephony layer introduces connection quality issues, audio codec variations, network jitter, and packet loss. Minor packet loss degrades audio quality, reducing ASR accuracy, leading to misunderstandings that trigger inappropriate responses.
The ASR layer adds transcription accuracy variations based on accent, background noise, speaking speed, and audio quality. According to industry analysis on voice AI observability, teams reduced end-to-end latency from 2 seconds to 1.1 seconds by switching LLM providers and optimizing prompt construction, demonstrating how optimization at one layer impacts overall performance.
Real-Time Latency Requirements
Unlike text applications, where 2-second response times remain acceptable, voice conversations demand sub-second latency to feel natural. Users expect immediate responses similar to human conversation patterns. According to research on voice agent performance, latency above 800ms creates noticeable pauses that damage conversation quality and user trust.
Time-to-first-token (TTFT) from LLMs becomes critical. Streaming responses help but introduce coordination complexity across STT, LLM, and TTS layers. Each processing stage adds latency that compounds across the full pipeline.
Conversation Quality Assessment
Evaluating multi-turn conversation quality requires different approaches than single-turn interactions. Teams must assess whether agents maintain context across exchanges, handle topic shifts gracefully, manage interruptions without breaking conversational flow, and guide conversations toward successful goal completion.
Traditional text-based evaluation metrics fail to capture voice-specific quality signals. Tone, hesitation, sighs, and frustration manifest in audio but disappear in text transcripts. Evaluation platforms must process actual audio to detect these critical quality indicators.
The 5 Best Voice Agent Evaluation Tools
Maxim AI
Platform Overview
Maxim AI provides an end-to-end platform for AI agent simulation, evaluation, and observability, designed to help teams ship voice agents reliably. Unlike point solutions focused solely on voice monitoring, Maxim AI delivers comprehensive lifecycle management spanning experimentation, simulation, evaluation, and production observability for multimodal agents, including voice applications.
Key Features
Full-Stack Voice Agent Workflow Support
Maxim supports the complete voice agent development lifecycle through integrated products. Playground++ enables rapid prompt iteration with version control for voice agent instructions and conversation flows. AI-powered simulation tests voice agents across hundreds of conversation scenarios and user personas before deployment.
The unified evaluation framework combines machine evaluators with human review workflows specifically designed for voice quality assessment. Production observability provides real-time monitoring with distributed tracing for voice pipelines and automated quality checks.
Multi-Turn Conversation Evaluation
Maxim enables evaluation at multiple granularity levels critical for voice agents. Span-level evaluation assesses individual ASR transcriptions, TTS generations, or tool calls. Trace-level evaluation examines complete conversation turns. Session-level evaluation analyzes entire multi-turn dialogues for goal completion, conversation flow quality, and user satisfaction.
This flexibility allows teams to pinpoint exact failure points. You can determine if poor performance stems from transcription errors (span-level), inappropriate LLM responses (trace-level), or conversation flow breakdown (session-level).
Voice-Specific Evaluators
Maxim's evaluator store includes evaluators for voice agent assessment, including conversation quality, instruction following, goal completion, context retention across turns, and latency tracking. Teams can create custom evaluators for domain-specific quality criteria such as compliance verification, sentiment assessment, or brand voice consistency.
Comprehensive Data Management
The Data Engine provides multi-modal dataset management supporting audio files, transcripts, and conversation metadata. Teams can continuously curate datasets from production conversations, enrich them with human annotations for quality assessment, and create targeted data splits for specific evaluation scenarios.
According to Maxim's simulation capabilities, teams can test voice agents across diverse user personas with varying speech patterns, accents, and conversation styles, identifying issues before production deployment.
Cross-Functional Collaboration
Maxim emphasizes collaboration between AI engineers, product managers, and QA teams. No-code evaluation configuration allows product teams to define conversation quality criteria without engineering dependencies. Custom dashboards track business-relevant metrics like call completion rates, average handling time, and user satisfaction indicators.
Best For
Maxim AI is ideal for teams requiring end-to-end lifecycle management for voice agents, cross-functional collaboration on voice quality optimization, multimodal agent architectures combining voice with other modalities, and enterprise deployment with comprehensive observability and compliance features.
Roark
Platform Overview
Roark specializes in production voice agent monitoring and call replay capabilities. According to their platform documentation, Roark has processed over 10 million minutes of calls, focusing on real-world performance validation through production call analysis.
Key Features
Roark captures production conversations and replays them against updated agent versions, cloning original caller voices for realistic testing. The platform monitors sentiment and vocal cues, detecting frustration, long pauses, sighs, and hesitation signals that text-based analysis misses. Built-in metrics track latency, instruction following, goal completion, and custom business objectives.
Best For
Roark works best for teams with substantial production voice traffic who iterate frequently on agent improvements and need detailed visibility into real-world performance patterns.
Coval
Platform Overview
Coval brings simulation methodology inspired by autonomous vehicle testing into voice AI. The platform emphasizes comprehensive pre-deployment testing through large-scale scenario simulation combined with post-deployment monitoring.
Key Features
Coval enables large-scale scenario simulation running thousands of virtual conversations across accents, edge cases, and stress conditions. The platform provides unified observability for production monitoring, including failed intents, latency tracking, and policy violations. Integration with CI/CD pipelines enables automated regression testing when prompts or code changes occur.
Best For
Coval suits teams prioritizing pre-deployment simulation to catch issues before production release, particularly those requiring compliance-aware testing and regression prevention through automated simulation runs.
Hamming AI
Platform Overview
Hamming AI focuses on stress testing voice agents at scale with emphasis on compliance and safety verification. According to research on voice observability, comprehensive monitoring across telephony, ASR, LLM, TTS, and integration layers prevents quality issues from reaching users.
Key Features
Hamming provides custom LLM-as-judge scorers for business-specific voice behaviors, real-time production monitoring with configurable alerts, cross-call pattern detection revealing systemic issues individual analysis would miss, and compliance verification ensuring regulatory requirements are met.
Best For
Hamming AI serves enterprise teams requiring comprehensive compliance testing, high-volume stress testing capabilities, and detailed observability across all voice pipeline layers.
Cekura
Platform Overview
Cekura offers a full QA pipeline from automated scenario generation through evaluation metrics to live monitoring. The platform emphasizes reducing the manual test creation burden through AI-generated test scenarios.
Key Features
Cekura automatically generates diverse test cases, including personas, accents, and background noise from agent descriptions. Custom evaluation metrics track instruction following, tool usage, interruption handling, and latency. The platform provides actionable insights with prompt-level recommendations for agent refinement.
Best For
Cekura works well for teams needing automated test generation to reduce QA workload, comprehensive evaluation metrics covering voice-specific quality dimensions, and continuous monitoring with actionable improvement recommendations.
Platform Comparison
| Feature | Maxim AI | Roark | Coval | Hamming AI | Cekura |
|---|---|---|---|---|---|
| Full Lifecycle Support | ✅ Complete | ⚠️ Monitoring Focus | ⚠️ Simulation Focus | ⚠️ Testing Focus | ✅ QA Pipeline |
| Multi-Turn Evaluation | ✅ Span/Trace/Session | ✅ Production Calls | ✅ Simulated Calls | ✅ Stress Tests | ✅ Automated Tests |
| Pre-Built Voice Evaluators | ✅ Extensive | ✅ Good | ✅ Good | ✅ Extensive | ✅ Good |
| No-Code Configuration | ✅ Yes | ⚠️ Limited | ⚠️ Limited | ⚠️ Limited | ✅ Yes |
| Simulation Capabilities | ✅ AI-Powered | ❌ Replay Only | ✅ Large-Scale | ✅ Stress Testing | ✅ Auto-Generated |
| Production Monitoring | ✅ Real-Time | ✅ Real-Time | ✅ Post-Deployment | ✅ Real-Time | ✅ Live Monitoring |
| Cross-Functional Collaboration | ✅ Full Support | ⚠️ Engineer-Focused | ⚠️ Engineer-Focused | ⚠️ Engineer-Focused | ⚠️ Engineer-Focused |
| Multimodal Support | ✅ Voice + Text + More | ❌ Voice Only | ❌ Voice Only | ❌ Voice Only | ⚠️ Limited |
| Data Curation | ✅ Data Engine | ⚠️ Basic | ⚠️ Basic | ⚠️ Basic | ⚠️ Basic |
| Deployment Options | ✅ Cloud/On-Prem/Air-Gapped | ✅ Cloud | ✅ Cloud | ✅ Cloud | ✅ Cloud |
Choosing the Right Tool
Selecting the appropriate voice agent evaluation platform depends on your development stage, application requirements, and team structure.
For Early Development: Teams in prototyping stages should prioritize experimentation support with flexible prompt testing. Maxim's Playground++ enables rapid iteration on voice agent instructions and conversation flows without production deployment complexity.
For Pre-Production Testing: Before deployment, a comprehensive simulation becomes critical. Maxim's AI-powered simulation tests agents across hundreds of user personas and conversation scenarios. Coval provides similar large-scale simulation capabilities focused on regression testing.
For Production Deployment: Live voice applications require robust monitoring. Maxim's observability suite offers real-time quality checks with distributed tracing across voice pipelines. Roark specializes in production call replay for iterative improvement. Hamming AI provides enterprise-grade monitoring with compliance verification.
Application Type Considerations: Transactional voice applications like appointment scheduling require detailed function call tracking and journey testing. Conversational applications like customer support need conversation-level quality assessment and context retention monitoring. Informational voice applications prioritize response accuracy and knowledge retrieval evaluation.
Team Structure: Engineering-only teams can work with any platform. Cross-functional teams including product managers and QA specialists benefit from Maxim's no-code evaluation configuration and custom dashboards enabling non-technical stakeholders to define quality criteria and track business metrics.
Multimodal Requirements: Teams building agents that combine voice with text, images, or other modalities need unified evaluation infrastructure. Maxim supports multimodal agent evaluation across all interaction channels. Voice-only platforms require separate tooling for other modalities.
Conclusion
Voice agent evaluation demands comprehensive visibility into ASR accuracy, conversation quality, latency performance, and goal completion across realistic user interactions. The five platforms reviewed provide different approaches tailored to specific evaluation needs.
Maxim AI stands out as the only platform providing end-to-end support spanning experimentation, simulation, evaluation, and production observability for voice and multimodal agents. The platform's unique capabilities in AI-powered simulation, multi-level evaluation granularity, and cross-functional collaboration tools eliminate tool sprawl that slows voice agent development.
Roark excels in production call replay and real-world performance analysis. Coval provides a comprehensive pre-deployment simulation with CI/CD integration. Hamming AI delivers enterprise-scale stress testing with compliance verification. Cekura offers automated test generation, reducing manual QA workload.
The optimal choice depends on whether you need comprehensive lifecycle management or specialized point solutions for specific evaluation stages. Teams building production-grade voice agents across multiple modalities benefit from Maxim's unified approach, accelerating development through integrated workflows from experimentation to production monitoring.
Explore Maxim AI's platform to see how end-to-end voice agent evaluation can transform your development workflow, or schedule a demo to discuss your specific voice AI requirements with our team.
Further Reading
Maxim AI Resources
- AI Agent Simulation and Evaluation
- Production Observability for AI Agents
- Evaluator Store: Pre-Built and Custom Metrics
- Data Engine for Multi-Modal Dataset Management
Industry Research
- Conversational AI Evaluation: Multi-Turn Dialogue Assessment
- Speech Recognition Quality in Production Systems
- Real-Time Voice AI Performance Optimization
- Evaluating LLM-Based Conversational Agents
Ready to elevate your voice agent evaluation workflow? Sign up for Maxim AI to start building more reliable voice applications, or book a demo to explore how our platform can accelerate your team's voice AI development velocity.


