What is an AI Gateway? A Complete Architecture Guide for Enterprise AI
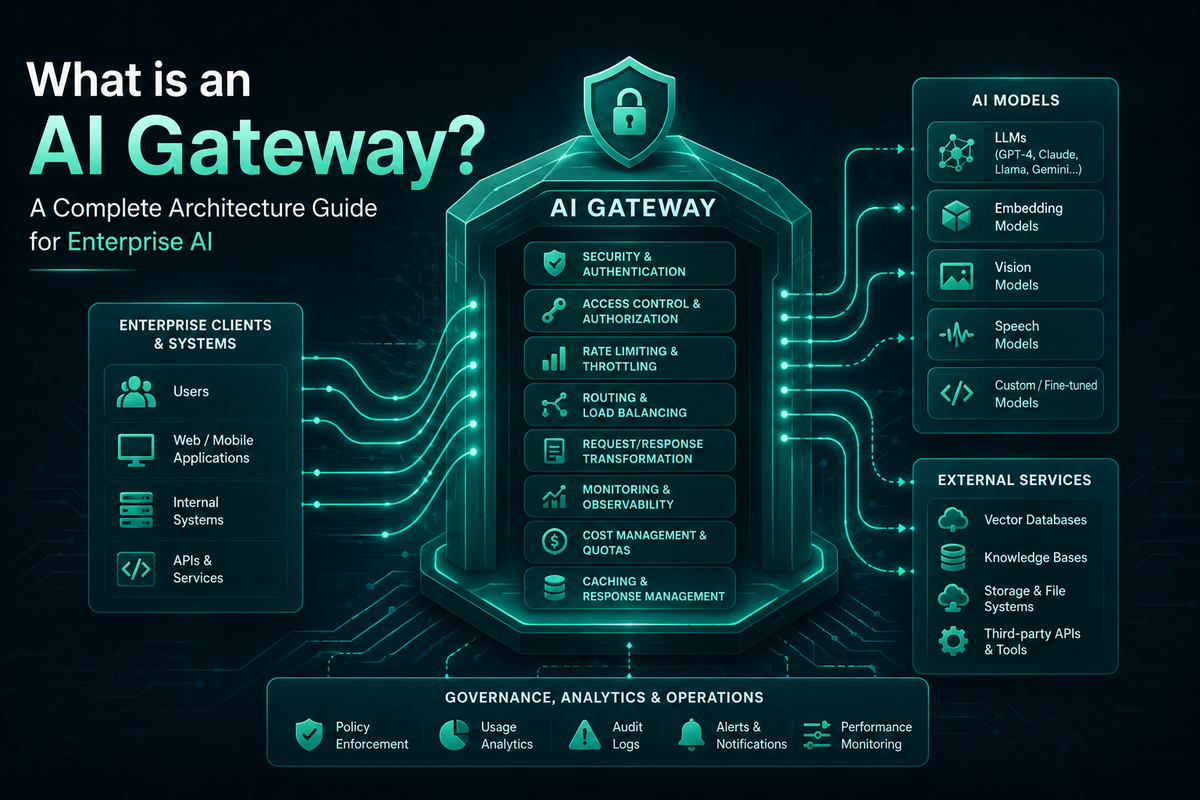
An AI gateway is the control plane for enterprise LLM traffic. Learn how AI gateway architecture handles routing, governance, caching, and observability at scale.
Enterprise AI teams are no longer running a single model against a single provider. Production stacks now mix OpenAI, Anthropic, AWS Bedrock, Google Vertex, and open-source models across multiple regions, business units, and use cases. An AI gateway is the infrastructure layer that sits between these applications and the underlying model providers, centralizing routing, governance, caching, security, and observability into a single control plane. Without one, teams face provider lock-in, runaway costs, inconsistent logging, and outages that ripple straight into customer experience. Bifrost, the open-source AI gateway from Maxim AI, is purpose-built for this layer, unifying access to 20+ providers through a single OpenAI-compatible API with only 11 microseconds of overhead at 5,000 requests per second. This guide explains what an AI gateway is, how its architecture works, and what to evaluate when adopting one for production AI workloads.
What Is an AI Gateway?
An AI gateway is a middleware layer that brokers, governs, and observes all traffic between AI-powered applications and large language model providers, model APIs, embedding services, and tool servers. It abstracts provider-specific SDKs behind a unified API, enforces policy and budgets, handles failover and caching, and produces structured telemetry for every request and response.
In a typical production architecture, every chat completion, embedding generation, image request, and tool invocation passes through the gateway. The gateway normalizes the request, applies governance rules, routes to the optimal provider, and returns a unified response. This decouples application code from individual provider SDKs and turns the AI stack into something that can be operated, audited, and scaled like any mature enterprise system.
AI Gateway vs API Gateway: Key Differences
Traditional API gateways were designed for stateless, predictable REST traffic. AI workloads have different characteristics: long-running streaming responses, token-based billing, semantically meaningful request payloads, model-specific error modes, and rapidly changing provider catalogs.
An AI gateway extends the API gateway pattern with capabilities specific to LLM traffic:
- Token-aware metering and cost attribution, not just request counts
- Semantic caching based on prompt similarity rather than exact URL matches
- Provider failover across heterogeneous APIs with different request and response shapes
- Streaming-first design for server-sent events and partial completions
- Tool and MCP orchestration for agentic workflows
- Content safety and guardrails for prompts, completions, and PII
A traditional API gateway can proxy LLM calls, but it cannot make intelligent routing decisions based on model capabilities, token budgets, or semantic content. An AI gateway is purpose-built for those tasks.
Core Components of AI Gateway Architecture
Enterprise AI gateway architecture typically includes six layers, each addressing a specific concern in production LLM operations:
- Provider abstraction layer: A unified API that normalizes requests across OpenAI, Anthropic, AWS Bedrock, Google Vertex, Azure OpenAI, and other model providers, exposing them through a single contract.
- Routing and load balancing: Logic for distributing traffic across providers, models, regions, and API keys based on latency, cost, availability, and routing rules.
- Reliability layer: Automatic failover, retries, circuit breakers, and health checks that keep applications running even when individual providers degrade or fail.
- Caching layer: Semantic and exact-match caching that reduces cost and latency for repeated or similar prompts.
- Governance plane: Virtual keys, budgets, rate limits, role-based access control, and audit logging that turn ad-hoc API key sprawl into managed enterprise infrastructure.
- Observability layer: Structured logs, metrics, and distributed traces for every request, exported via OpenTelemetry or Prometheus to existing monitoring stacks.
Modern AI gateways extend this stack with an additional layer for Model Context Protocol (MCP) tool execution, turning the gateway into a coordination point for agentic workflows that span multiple models, tools, and external services.
Why Enterprises Need an AI Gateway
Three forces have made the AI gateway pattern essential for production AI:
Provider fragmentation. Every major LLM vendor exposes a different API contract, authentication scheme, error model, and rate limit structure. Hard-coding to one vendor creates lock-in; supporting many creates integration sprawl. A gateway removes this duplication and lets teams change providers without changing application code.
Multi-model workloads. Teams increasingly route reasoning, summarization, coding, and embeddings to different models for cost and quality reasons. Doing this in application code is brittle. A gateway makes routing a configuration decision rather than a code change.
Governance and compliance. Enterprise AI must comply with frameworks such as the NIST AI Risk Management Framework and the OWASP Top 10 for LLM Applications. Centralizing AI traffic through a gateway is the cleanest way to enforce policy, log access, and maintain audit trails consistently across teams. Gartner has projected that by 2028, 30% of the increased demand for APIs will come from AI and LLM-based tools, making dedicated AI gateway infrastructure an architectural necessity rather than an optional layer.
How Bifrost Implements Enterprise AI Gateway Architecture
Bifrost is built in Go for low-latency, high-throughput LLM traffic. In sustained benchmarks at 5,000 requests per second, Bifrost adds only 11 microseconds of overhead per request. The Bifrost performance benchmarks document the methodology and results in detail.
Bifrost implements each layer of this architecture as follows:
- Unified API: A single OpenAI-compatible interface that works as a drop-in replacement for the OpenAI, Anthropic, AWS Bedrock, Google GenAI, LiteLLM, and LangChain SDKs. Teams change only the base URL in existing code.
- Multi-provider routing: Support for 20+ providers through one API, with routing rules that direct traffic to specific models, providers, or keys based on use case.
- Automatic failover and load balancing: Provider fallbacks and weighted distribution across API keys keep traffic flowing when a provider degrades or goes down.
- Semantic caching: Semantic caching reduces cost and latency by returning cached responses for prompts that are semantically similar, not just identical.
- Governance via virtual keys: Virtual keys are the primary unit of governance, carrying per-consumer budgets, rate limits, model access permissions, and MCP tool filters. Teams can review the Bifrost governance capabilities for enterprise rollout patterns.
- Observability: Native Prometheus metrics, OpenTelemetry (OTLP) tracing, and integrations with Grafana, New Relic, Honeycomb, and Datadog.
- MCP gateway: Bifrost acts as both an MCP client and server, centralizing tool connections, OAuth, and policy enforcement for agentic workflows. The Bifrost MCP gateway covers token cost reduction and access control patterns in depth.
Bifrost also supports clustering, in-VPC deployments, RBAC with OpenID Connect providers like Okta and Entra, vault integrations for key management, and immutable audit logs for SOC 2, GDPR, HIPAA, and ISO 27001 compliance.
AI Gateway Deployment Patterns
Enterprise teams typically choose between three deployment patterns for an AI gateway:
- Centralized gateway: A single cluster handles all AI traffic for the organization. This pattern maximizes policy consistency and observability but requires careful capacity planning at scale.
- Two-tiered gateway: A primary central gateway works alongside lightweight micro-gateways closer to specific services or teams. This improves locality and scalability while preserving central policy control.
- In-VPC or on-prem deployment: The gateway runs entirely within a private network for regulated workloads. Bifrost supports in-VPC deployments and air-gapped installs for industries with strict data residency requirements.
The right pattern depends on traffic volume, team structure, regulatory exposure, and how aggressively the organization needs to enforce cross-team governance. For a structured evaluation framework, the LLM Gateway Buyer's Guide provides a detailed capability matrix across performance, governance, and observability.
Key Considerations When Adopting an AI Gateway
Before standardizing on an AI gateway, evaluate these dimensions:
- Performance overhead: Latency added by the gateway directly affects user-facing applications. Look for sub-millisecond overhead at production load.
- Provider coverage: The gateway should support all current and likely future providers without requiring a vendor change.
- Governance depth: Virtual keys, hierarchical budgets, rate limits, and RBAC should be first-class features, not afterthoughts.
- Observability integrations: Native OpenTelemetry and Prometheus support is essential; proprietary telemetry formats create lock-in.
- MCP and tool support: As agentic workloads expand, MCP gateway functionality becomes a hard requirement rather than a nice-to-have.
- Deployment flexibility: Self-hosting, in-VPC, and on-prem options matter for regulated industries.
- Open source versus proprietary: Open-source gateways like Bifrost provide transparency, auditability, and the ability to extend the gateway with custom Go or WASM plugins.
Getting Started with Bifrost as Your AI Gateway
Production AI cannot run on direct provider SDK calls forever. An AI gateway is the architectural pattern that turns a fragile, provider-coupled stack into a governed, observable, and reliable platform. Bifrost delivers each layer of the enterprise AI gateway architecture, unified API access, intelligent routing, semantic caching, governance, observability, and MCP tool orchestration, with the lowest measured overhead in the category.
To see how Bifrost can simplify your AI infrastructure, book a demo with the Bifrost team or explore the Bifrost product page to learn more about deployment options.