Enterprise AI Gateway: Per-User Rate Limiting, Budget Controls, and Automatic Fallbacks

How an enterprise AI gateway enforces per-user rate limiting, budget controls, and automatic fallbacks to keep LLM spend and uptime predictable at scale.
Enterprise LLM usage is scaling faster than the controls built to govern it. Platform teams are fielding the same three problems at once: one agent or one power user consumes the entire provider quota and starves everyone else, monthly LLM invoices arrive with no attribution to a team or customer, and a single upstream outage takes production down. An enterprise AI gateway is the control plane that solves all three in one place, and Bifrost was built specifically to enforce per-user rate limiting, budget controls, and automatic fallbacks without slowing the hot path. According to Gartner research reported by Kong, more than 80% of enterprises will have deployed generative AI or used GenAI APIs by 2026, up from 5% in 2023. At the same time, McKinsey research cited in industry governance coverage found that only 28% of organizations have a board-level AI governance strategy. The gap between deployment and governance is not theoretical.
Bifrost is an open-source AI gateway used by over 1,100 organizations and adds only 11 microseconds of overhead at 5,000 requests per second, which makes it viable as a mandatory in-path control for production traffic. This post walks through how Bifrost implements the three controls most enterprise teams are missing, and how they compose into a single governance model.
What an Enterprise AI Gateway Must Do
An enterprise AI gateway is the request-layer control plane that sits between application code and every LLM provider, enforcing identity, cost, and reliability policies on every call. The gateway pattern replaces per-provider SDK sprawl with a single OpenAI-compatible API and moves governance out of application code. At a minimum, an enterprise-ready gateway must provide:
- Per-consumer identity: A unique credential for every team, agent, customer, or user so usage can be attributed and limited.
- Budget controls: Dollar-based spending caps at multiple organizational levels, not just token counts.
- Rate limiting: Independent token and request throttles per consumer, with configurable windows.
- Automatic fallbacks: Cross-provider failover when a primary returns errors, exhausts retries, or exceeds budget.
- Observability: Real-time usage tracking and audit logs for every request.
The three features covered in this post, per-user rate limiting, budget controls, and automatic fallbacks, are the minimum set that separates a developer proxy from an enterprise-grade AI gateway.
Per-User Rate Limiting: Preventing Noisy Neighbors and Runaway Agents
Per-user rate limiting caps the volume of requests and tokens any single consumer can send to LLM providers in a given window, which prevents one noisy team or one misbehaving agent from exhausting shared provider quotas. Without it, a single Python notebook in a retry loop or a Full Auto coding agent running overnight can burn through a week of capacity in an hour.
Bifrost implements rate limiting through virtual keys, which are the primary governance entity in the gateway. Each virtual key is a unique sk-bf-* credential issued to a team, an agent, an internal service, or an external customer. The key is passed in the x-bf-vk header (or via Authorization, x-api-key, or x-goog-api-key to match OpenAI, Anthropic, and Google SDK conventions), and Bifrost enforces the associated limits on every request before the upstream call is made.
Two limit types are supported in parallel:
- Token limits: Maximum prompt plus completion tokens per window, for example 50,000 tokens per hour.
- Request limits: Maximum API calls per window, for example 200 requests per minute.
Reset windows are fully configurable: 1m, 5m, 1h, 1d, 1w, 1M, 1Y. A typical enterprise pattern is a short request window (1 minute) to catch runaway loops and a longer token window (1 hour or 1 day) to cap sustained throughput. Bifrost also supports provider-level rate limits inside a single virtual key, so a key with access to both OpenAI and Anthropic can throttle each provider independently. When a provider exceeds its rate limit, it is excluded from routing, and traffic automatically shifts to the remaining providers in the same key.
When a limit is hit, Bifrost returns a structured 429 error with the exact counter and reset duration:
{
"error": {
"type": "rate_limited",
"message": "Rate limits exceeded: [token limit exceeded (1500/1000, resets every 1h)]"
}
}
This matters in practice because it lets client code distinguish a gateway-enforced throttle from an upstream provider throttle and react accordingly, instead of blind exponential backoff.
Budget Controls: Hierarchical Cost Governance Across Teams and Customers
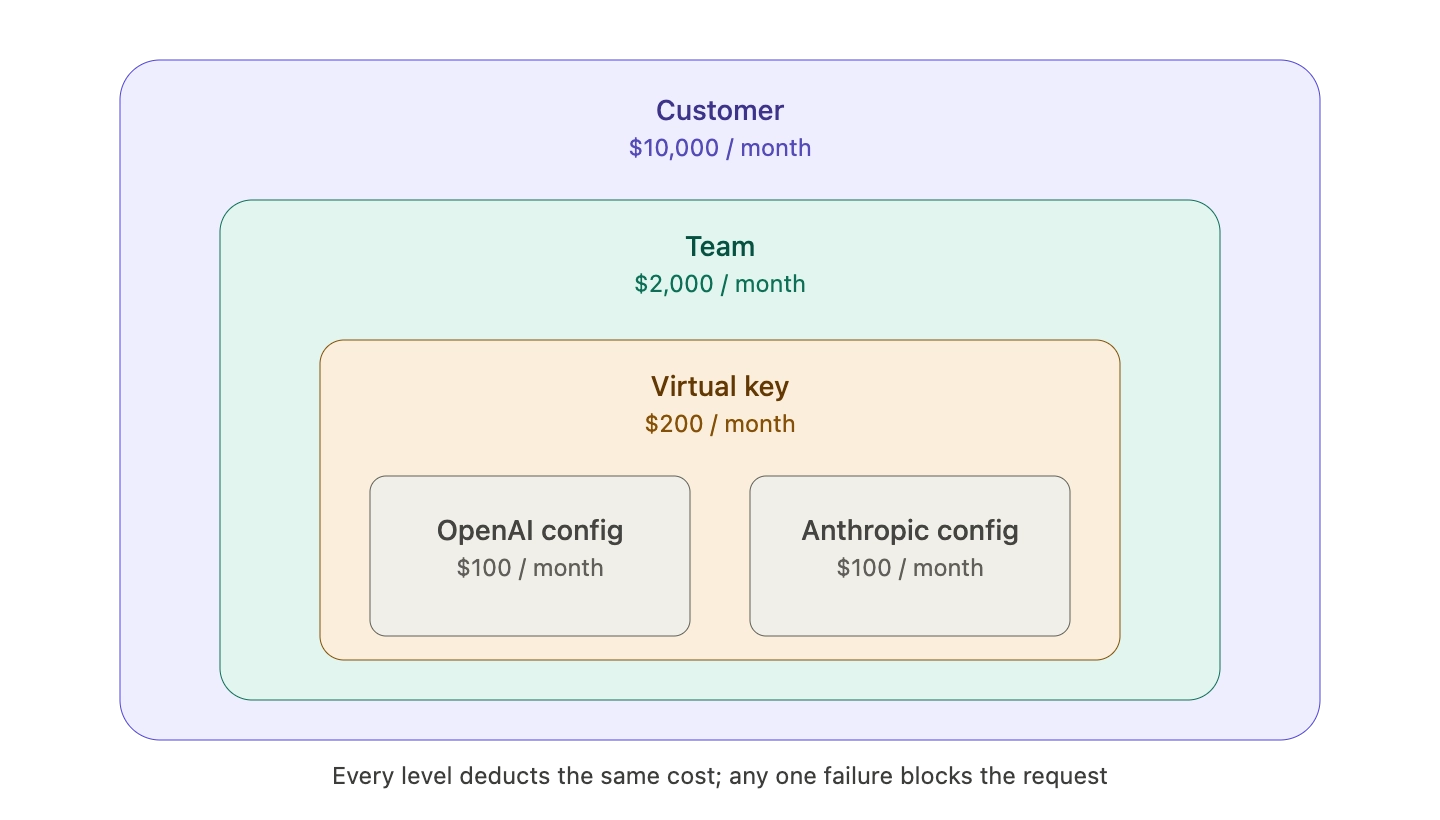
Budget controls cap dollar spend at every organizational level in a single policy chain, so a runaway agent cannot exceed its own budget, its team's budget, or the parent organization's budget. Bifrost's budget and limits model is hierarchical by design: every level has its own independent budget, and a request must pass all applicable checks to proceed.
The hierarchy has three layers above the virtual key, plus an optional fourth layer inside it:
- Customer: Top-level entity, typically an external tenant or major business unit.
- Team: Department-level grouping inside a customer.
- Virtual Key: The credential held by the actual consumer (agent, service, user).
- Provider Config: Per-provider budget inside a single virtual key.
Every level tracks its own usage and can enforce its own monthly, weekly, daily, or calendar-aligned reset. A single request deducts cost from every applicable level at once. If any one of them is exceeded, the request fails with a 402 budget_exceeded error and the exact overage.
A typical enterprise configuration looks like this:
- Customer budget: $10,000 per month for Acme Corp.
- Team budget: $2,000 per month for the engineering team inside Acme.
- Virtual key budget: $200 per month for one developer's coding agent.
- Provider config budget: $100 per month for Anthropic models inside that key, $100 for OpenAI.
This structure gives finance and platform teams two levers most gateway products lack. First, per-user caps stop individual consumers from burning team budget on day three of the month. Second, customer-level caps give SaaS teams a way to price-meter external tenants without a separate metering layer. Budgets support calendar-aligned resets (reset at UTC midnight for daily, first of the month for monthly) or rolling windows, which lets finance teams align AI cost reporting with the rest of their billing cycle.
Internally, costs are calculated from real-time provider pricing, actual token usage from responses, and request type (chat, embeddings, speech, transcription), with automatic discounts applied for cached responses and batch operations. Teams get accurate dollar attribution on every request, not token estimates that drift from invoice reality. For platform teams evaluating the full governance feature set, the Bifrost governance resource page covers access control, audit logs, and SSO alongside the budget and rate limit primitives.
Automatic Fallbacks: Reliability When Providers Fail
Automatic fallbacks move a request to a different provider or model when the primary returns errors, exhausts retries, or hits a budget or rate limit, with no change to application code. Bifrost's retries and fallbacks system is two nested layers: retries handle transient errors inside a single provider, and fallbacks cross provider boundaries once retries are exhausted.
The retry layer uses exponential backoff with jitter and, starting in v1.5.0-prerelease4, rotates to a fresh API key from the pool when it detects a 429 response. This means a single OpenAI account with three API keys and max_retries: 5 will cycle through all three keys (twice) before giving up, which recovers from most per-key rate-limit events without any fallback needed.
When retries are fully exhausted, Bifrost moves to the next provider in the fallback chain. Fallbacks are passed per-request in a fallbacks array:
curl -X POST <http://localhost:8080/v1/chat/completions> \\
-H "Content-Type: application/json" \\
-d '{
"model": "openai/gpt-4o-mini",
"messages": [{"role": "user", "content": "Explain quantum computing"}],
"fallbacks": [
"anthropic/claude-3-5-sonnet-20241022",
"bedrock/anthropic.claude-3-sonnet-20240229-v1:0"
]
}'
Each fallback gets its own full retry budget. Plugins (semantic cache, governance, logging) run fresh for every fallback attempt, so a cached response on the fallback provider still short-circuits the network call. The response includes an extra_fields.provider value so applications can log which provider actually served each request.
Fallbacks also compose with governance. If a virtual key's OpenAI budget is exhausted and Anthropic is configured as a weighted alternative on the same key, traffic shifts automatically without the application ever seeing a 402. This is the key architectural idea: budget controls and automatic fallbacks are not separate features, they are two sides of the same routing decision. A provider that has exceeded its budget or rate limit is simply excluded from the routing pool, and the fallback chain takes over.
How These Three Controls Work Together in Bifrost
In a typical production request, Bifrost evaluates policies in a fixed order before any upstream call is made:
- Authenticate the virtual key and confirm it is active.
- Check access control: Is the requested model allowed on this key?
- Check rate limits at the provider-config level, then the virtual key level.
- Check budgets at the provider-config level, then the virtual key, then the team, then the customer.
- Route to a provider that passes all checks, using configured weights.
- On failure, retry the same provider with exponential backoff and key rotation.
- On exhaustion, fall back to the next provider in the chain.

Every step happens in the 11-microsecond overhead window at 5,000 RPS, so the policy layer does not become the new bottleneck. Teams evaluating gateways for production traffic can review the LLM Gateway Buyer's Guide for a full capability matrix across performance, governance, and reliability dimensions.
Deployment Patterns for Enterprise Teams
Three deployment patterns come up repeatedly in enterprise Bifrost rollouts:
- Internal multi-team platform: One Bifrost deployment serves every team. Each team gets a customer entity, each squad inside a team gets a team entity, and each agent or service gets its own virtual key. Platform team controls provider credentials centrally; application teams see only their virtual keys.
- External SaaS metering: Bifrost sits between the product and LLM providers. Each paying customer becomes a customer entity with a monthly budget that matches their plan. When a customer hits their cap, further requests fail gracefully with a
402, and the product can surface an upsell prompt. - Agentic workload isolation: Each autonomous agent gets its own virtual key with a small budget, a tight rate limit, and a curated model allowlist. Runaway agents self-terminate at the gateway, before they can drain the team's budget or trigger provider throttles that affect other workloads.
All three patterns depend on the same three primitives (per-user rate limiting, hierarchical budget controls, automatic fallbacks), which is why they are best treated as a single governance decision rather than three independent features.
Start with Bifrost Today
Per-user rate limiting, budget controls, and automatic fallbacks are the minimum governance layer for any enterprise AI gateway running real production traffic. Bifrost provides all three as open-source, policy-driven primitives that are enforced at 11 microseconds of overhead per request, and over 1,100 organizations have already deployed it in front of their LLM workloads. To see how Bifrost can replace fragmented per-provider governance with a single control plane across 20+ LLM providers, book a demo with the Bifrost team and we will walk through a reference architecture for your environment.


